AgentCore Evaluation 팀의 김무현 SA(데이터 사이언티스트)가 직접 만들고 있는 서비스를 발표. 핵심 메시지: "에이전트는 소리 없이 실패한다. LLM·Tool·프롬프트의 비결정성 때문에 지속적·자동화된 평가 루프(Inner / Outer / Production) 가 없으면 운영 환경에서 무너진다." 다루는 두 서비스: AgentCore Evaluation (완전관리형, 운영용) + Strands Evaluations (OSS, 개발용) + 새 출시 Strands Evaluations Detector.

| 단계 | 무엇 | 인간 감독 |
|---|---|---|
| 생성형 AI 어시스턴트 | 규칙 집합 준수, 반복 작업 자동화 | 증가 (많음) |
| 생성형 AI 에이전트 | 단일 목표 달성, 더 광범위한 작업 처리, 전체 워크플로우 자동화 | 중간 |
| 에이전트 AI 시스템 | 완전 자율, 멀티 에이전트 시스템, 인간의 논리 및 추론 모방 | 감소 (적음) |
→ 자율성 및 비즈니스 영향력 증가.
"인간의 논리·추론을 모방하는 에이전트로 진화하기 때문에 비즈니스 영향력이 점점 커진다. 그런데 우리는 이 에이전트를 신뢰할 수 있을까?" — 김무현
신뢰를 보장하지 못하면 고객 경험 보장 불가 → 프로젝트 실패.

"에이전트를 구성하는 요소들의 특징 때문에 우리의 밤잠을 설치게 됩니다."
| # | 도전과제 | 의미 |
|---|---|---|
| ① | 설계상 비결정론적 | LLM 기반이라 동일 입력 → 동일 출력 보장 안 됨. "테스트에선 잘 됐는데 운영에서 안 된다" 는 피드백의 근본 원인 |
| ② | 잘못된 도구, 잘못된 파라미터 | 다양한 도구 선택 가능 → 잘못된 도구 선택, 도구는 맞는데 파라미터 잘못 줄 수도 |
| ③ | "더 나음"을 측정할 방법 없음 | 프롬프트에 점 하나만 찍어도 결과가 완전히 달라짐. 변경이 정말 개선인지 측정 불가 |
| ④ | 자동 회귀 오류 | "새 모델로 바꿨으니 무조건 더 좋겠지" 가정은 위험. 모델/프롬프트/도구 변경 때마다 회귀 가능 |
→ 모델 업데이트 · 에이전트 새 버전 · 소스 프롬프트 수정 · Tool 추가/제거 — 이런 변경 때마다 지속 평가 필요.

개발자가 끊임없이 확인해야 하는 4가지.
→ 이 네 가지를 지속적으로 평가하지 않으면 운영 환경에서 안정적으로 사용 불가.

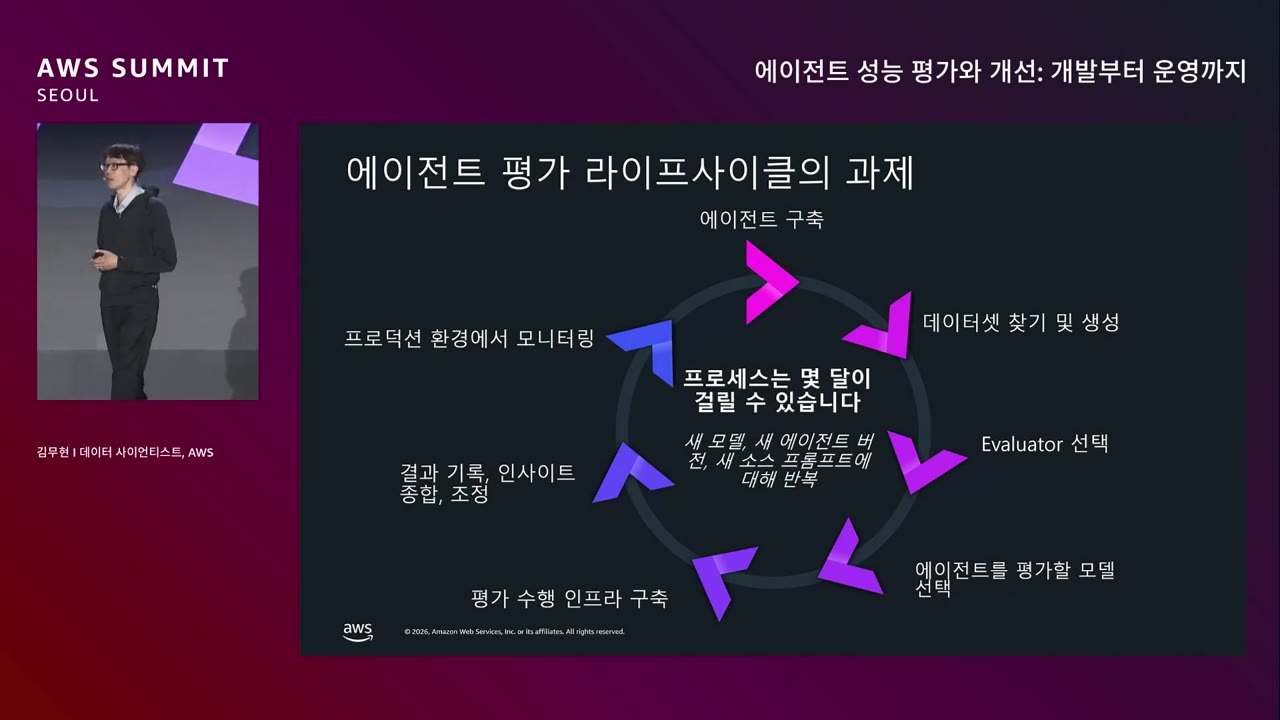
평가 파이프라인을 처음부터 구축하면 수개월 소요.
Mermaid스크롤로 확대 · 드래그로 이동
→ 이 모든 단계를 매번 직접 구축해야 한다는 게 페인 포인트.
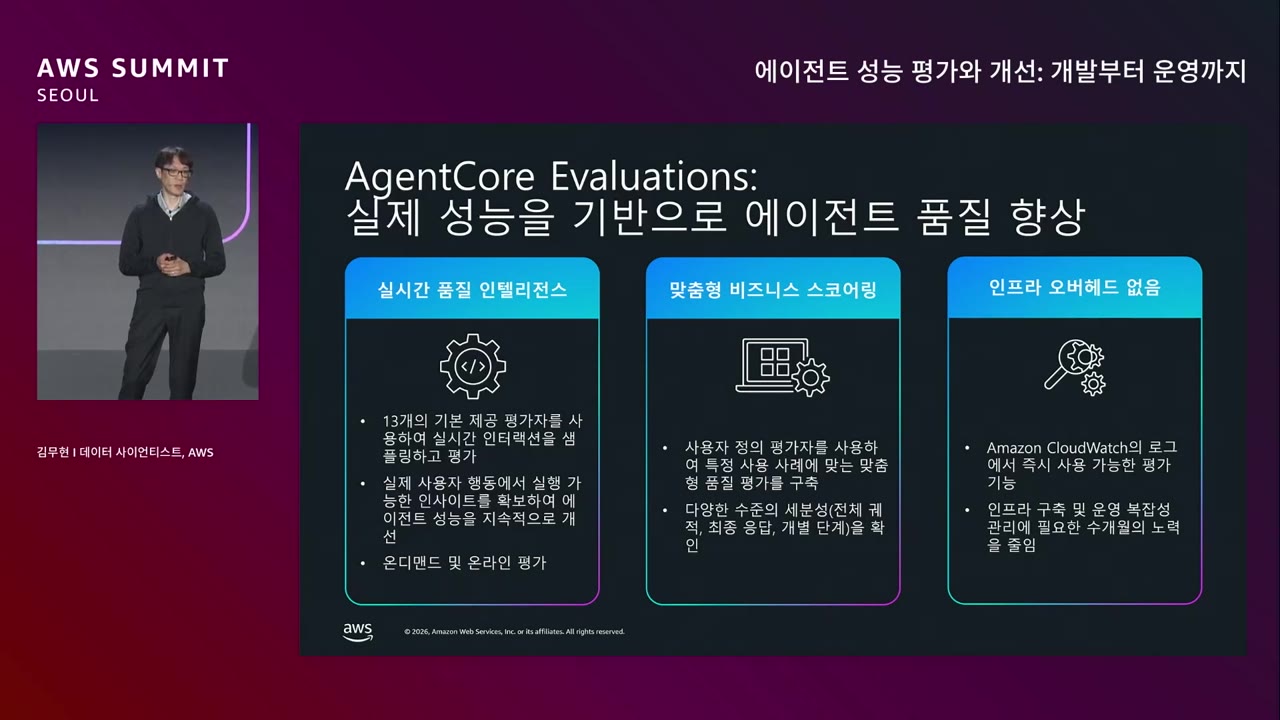
| ① 실시간 품질 인텔리전스 | ② 맞춤형 비즈니스 스코어링 | ③ 인프라 오버헤드 없음 |
|---|---|---|
| 13개의 기본 제공 평가자 사용하여 실시간 인터랙션을 샘플링하고 평가 | 사용자 정의 평가자를 사용하여 특정 사용 사례에 맞는 맞춤형 품질 평가 구축 | Amazon CloudWatch의 로그에서 즉시 사용 가능한 평가 기능 |
| 실제 사용자 행동에서 실행 가능한 인사이트를 확보하여 에이전트 성능을 지속적으로 개선 | 다양한 수준의 세분성 (전체 궤적, 최종 응답, 개별 단계) 을 확인 | 인프라 구축 및 운영 복잡성 관리에 필요한 수개월의 노력을 줄임 |
| 온디맨드 및 온라인 평가 | (완전관리형) |
→ 핵심 차별점: Trace 기반 동작 → 운영 중인 에이전트에 영향 없음.
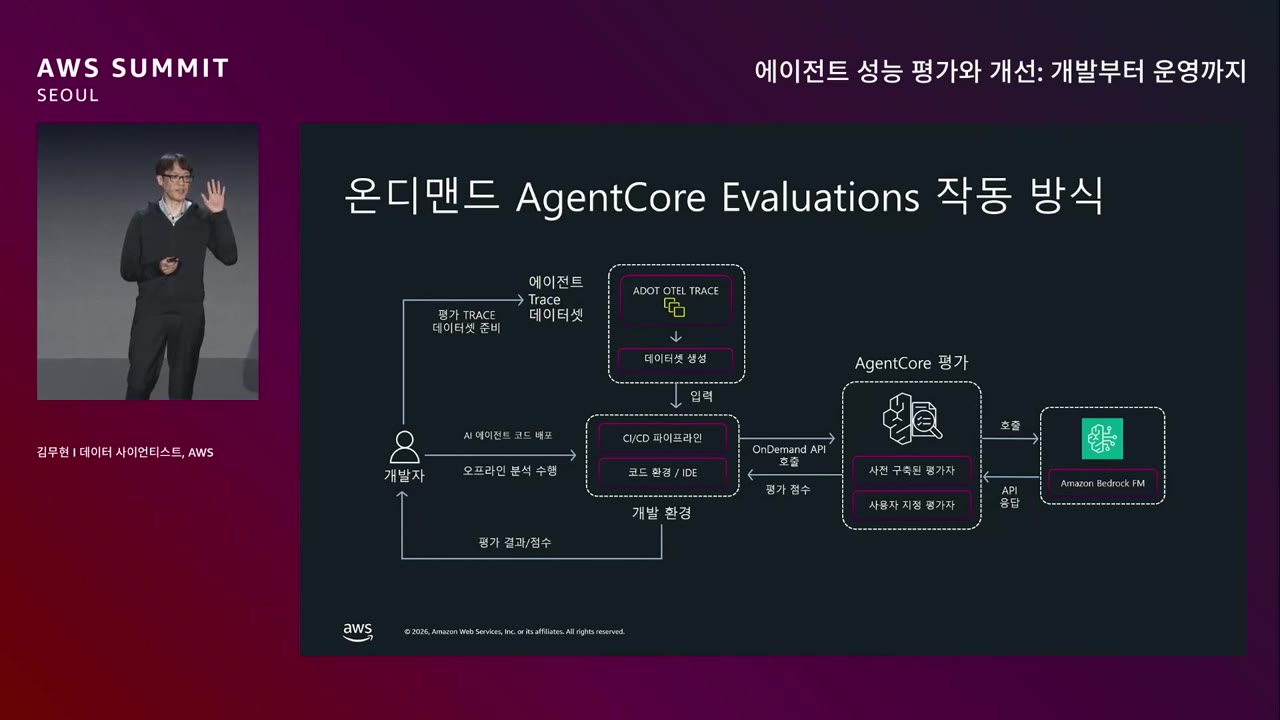
Mermaid스크롤로 확대 · 드래그로 이동
핵심 메커니즘.

| 시점 | 방법 | 트리거 |
|---|---|---|
| 배포 전 / 출시 전 벤치마킹 | On-Demand 평가 | 개발자가 데이터셋 + Evaluator 선택 후 수동 실행 |
| 운영 환경 배포 후 | Online 평가 | 사용자가 에이전트를 사용 → trace 생성 → 자동 평가 → 라이브 대시보드 |
On-Demand 동작 흐름.
Mermaid스크롤로 확대 · 드래그로 이동
"어제오늘 여러 고객 미팅을 해봤는데 가장 큰 페인 포인트는 '데이터가 없는데 어떻게 Evaluation 을 시작하냐' 입니다." — 김무현
작은 에이전트 유닛 테스트는 프롬프트 5–10개로 시작 가능. 하지만 프로덕션에는 대용량·다양한 데이터셋이 필요.
User Simulator가 설정할 수 있는 것.
활용 가치 4가지.
| 가치 | 의미 |
|---|---|
| 다양한 표현으로 테스트 | 매번 다른 문구·경로를 생성해 엣지 케이스 발견 |
| 자유 대화 평가 | 고정 스크립트 대신 실제 사용자 행동을 현실적으로 재현 |
| 시나리오 커버리지 확장 | 페르소나·목표만 정의하면 대화 자동 생성 |
| 다양성 기반 회귀 테스트 | 동일 의도의 다양한 표현에 일관 대응하는지 검증 |
→ "운영 환경에서 사용자는 굉장히 창의적이다. 엣지 케이스를 테스트셋에 포함시키는 게 중요하다."

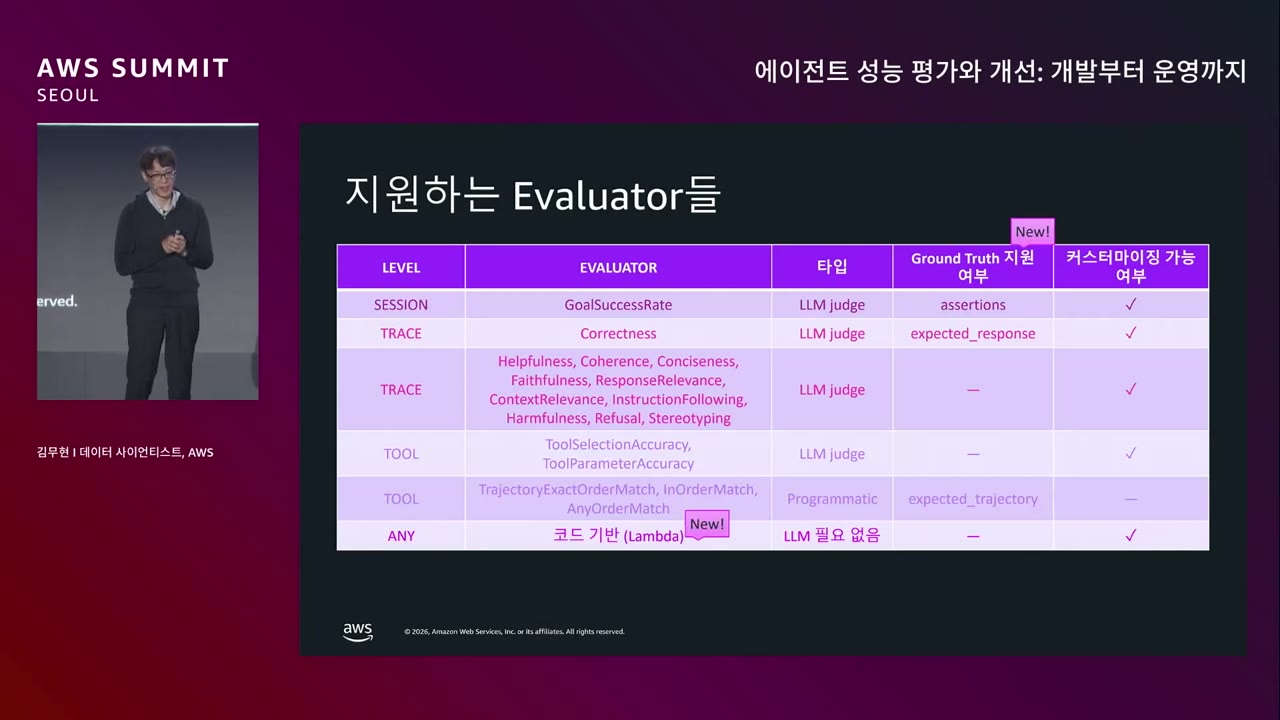
| LEVEL | EVALUATOR | 타입 | Ground Truth 지원 (NEW!) | 커스터마이징 |
|---|---|---|---|---|
| SESSION | GoalSuccessRate | LLM judge | assertions | ✓ |
| TRACE | Correctness | LLM judge | expected_response | ✓ |
| TRACE | Helpfulness, Coherence, Conciseness, Faithfulness, ResponseRelevance, ContextRelevance, InstructionFollowing, Harmfulness, Refusal, Stereotyping | LLM judge | — | ✓ |
| TOOL | ToolSelectionAccuracy, ToolParameterAccuracy | LLM judge | — | ✓ |
| TOOL | TrajectoryExactOrderMatch, InOrderMatch, AnyOrderMatch | Programmatic | expected_trajectory | — |
| ANY | 코드 기반 (Lambda) (NEW!) | LLM 필요 없음 | — | ✓ |
핵심 인사이트.
SESSION (전체 대화) / TRACE (단일 턴) / TOOL (도구 호출)→ 비즈니스 로직·정형 형식 검증이 필요한 경우 비싼 LLM 안 쓰고 코드 기반으로 가능.
"LLM judge Evaluator가 아닌 여러분이 만든 파이썬 코드 기반으로 Evaluation 을 수행 → 저렴한 비용 + 동일 입력에 동일 결과 (100% 확신)."
| # | 시나리오 | 의미 |
|---|---|---|
| 1 | CI/CD 회귀 게이팅 | CI/CD 파이프라인에 Evaluator 를 게이트로 두고 회귀 자동 차단 |
| 2 | 대규모 구조화된 출력 검증 | JSON 포맷 필수 필드 검증, SQL 유효성 검사 등. LLM 으로 하면 비용 폭주, 코드로는 전체 수에 대해 검증 가능 |
| 3 | 정밀도 및 정확한 검사 | 논리적으로 구현 가능한 평가 기준 |
| 4 | 하이브리드 평가 | LLM + 코드를 코드 기반 Evaluator 안에 통합 → 별도 파이프라인 안 만들고 복잡한 평가 구현 |
→ "SQL 유효성, JSON 필수 필드 같은 건 LLM 안 쓰는 게 맞다."

참조 입력: 이 세 필드의 임의 조합을 평가자 호출에 전달.
| 형태 | 의미 | 사용 시기 | 평가자 |
|---|---|---|---|
| Assertion (어설션) | 응답이 반드시 충족해야 하는 자유 형식 텍스트 사실 | 규정 준수 (면책 조항 포함 필수) / 어조 (공감적이어야 함) / 안전 (자해 권장 X) / 정확도 (가격 정확) | Builtin.GoalSuccessRate |
| Expected Response (예상 응답) | 에이전트의 최종 답변이 무엇을 말해야 하는지 | FAQ 봇 (정확 답변) / 수학·금융 (정확 결과) / 회귀 (정상 상태와 비교) / 분별 (추적 ID를 답변에 매핑) | Builtin.Correctness |
| Expected Trajectory (예상 궤적) | 에이전트가 반드시 호출해야 하는 순서가 지정된 도구 이름 | 다단계 워크플로 (순서 중요) / 보안 (실행 전 반드시 확인) / 감사 (각 단계 수행 증명) / 테스트 (단축키/건너뛰기 버그 포착) | Builtin.TrajectoryExactOrderMatch, InOrder, AnyOrder |
코드 예시 (슬라이드).
Pythonassertions = [ "가격이 존재함", "어조가 공감적임" ] expected_response = "환불 금액 $120이 처리되었으며 영업일 기준 3–5일 이내에 완료됩니다." expected_trajectory = [ "check_warranty", "create_rma" ]
"시스템 프롬프트에 인스트럭션을 열심히 줘도 인스트럭션은 인스트럭션일 뿐, 에이전트가 그걸 따른다는 보장은 어렵다. 따라서 Expected Trajectory 기반 평가가 반드시 필요." — 김무현

평가만 하고 끝나면 안 되고 고쳐야한다. 시스템 프롬프트? 도구 디스크립션? 어느 부분?
AgentCore Optimization의 흐름.
Mermaid스크롤로 확대 · 드래그로 이동
"최적화된 프롬프트를 바로 운영에 적용하시는 분 있으신가요? 저는 그렇게 용감하지 않습니다." — 김무현 → A/B 테스트 기능이 AgentCore에 추가되어 구버전 vs 신버전 50:50 트래픽으로 운영하면서 Evaluation 으로 관찰 후 이관 가능.
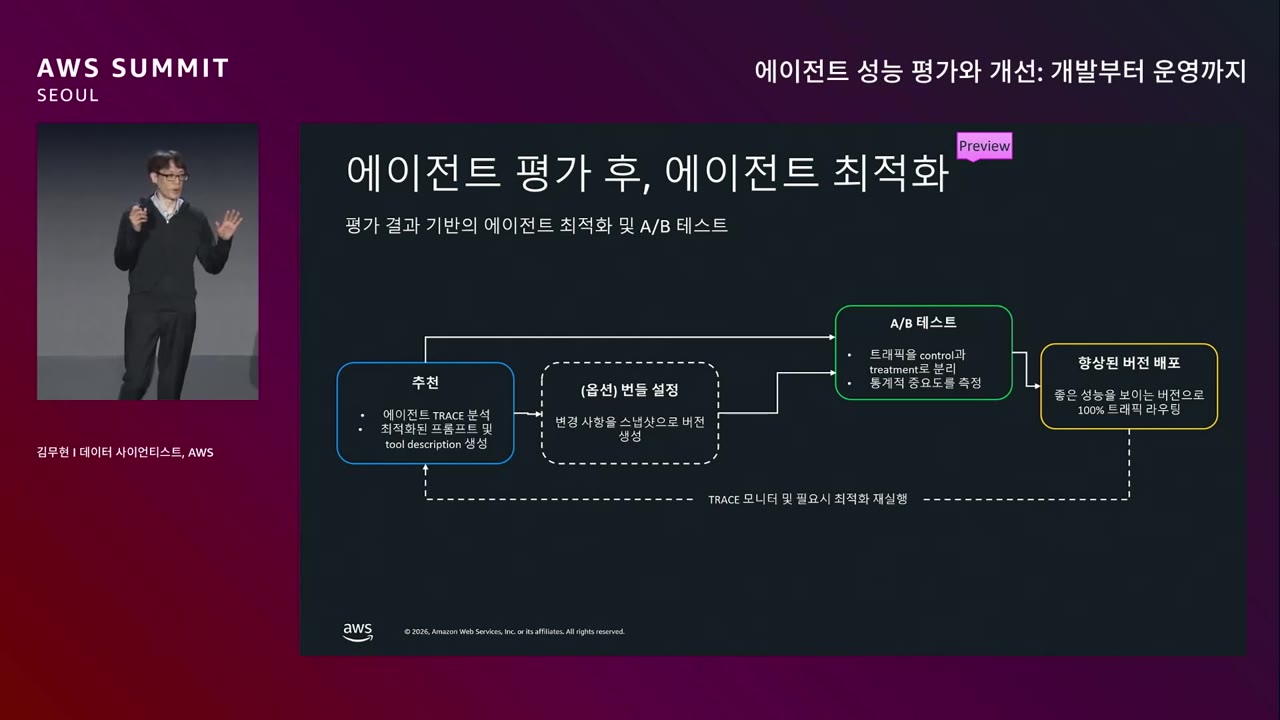
"개발 단계에서 AgentCore Evaluation 을 항상 호출해서 하라고 하면 거부감 또는 자유도가 낮다는 피드백이 있다." → 개발은 Strands, 운영은 AgentCore로 역할 분담.
| 개발 단계 | 운영 환경 배포 | 운영 |
|---|---|---|
| 데이터셋 시뮬레이션 (Strands) | 적은 양의 ground truth 검증 (Strands) | 사용자의 사용 현황 모니터링 (AgentCore) |
| Ground truth evaluation (Strands) | 대규모 실데이터 기반의 LLM as Judge (AgentCore) | 업데이트에 따른 변화 감지 (AgentCore) |
| LLM as Judge Evaluation (Strands와 AgentCore) | Ground truth 와 non-annotated 데이터셋 간의 조정 | |
| Pass / fail 판단 | ||
| CI/CD 통합 |
→ Strands Evaluations 는 에이전트 설정을 통한 실험 + Ground Truth 시뮬레이션 비교 가능. AgentCore Evaluation 이 할 수 있는 거의 모든 기능을 자체 처리 가능하지만, 파이프라인 구성은 직접 해야 함 → 운영 환경으로 넘어가면 AgentCore 권장.

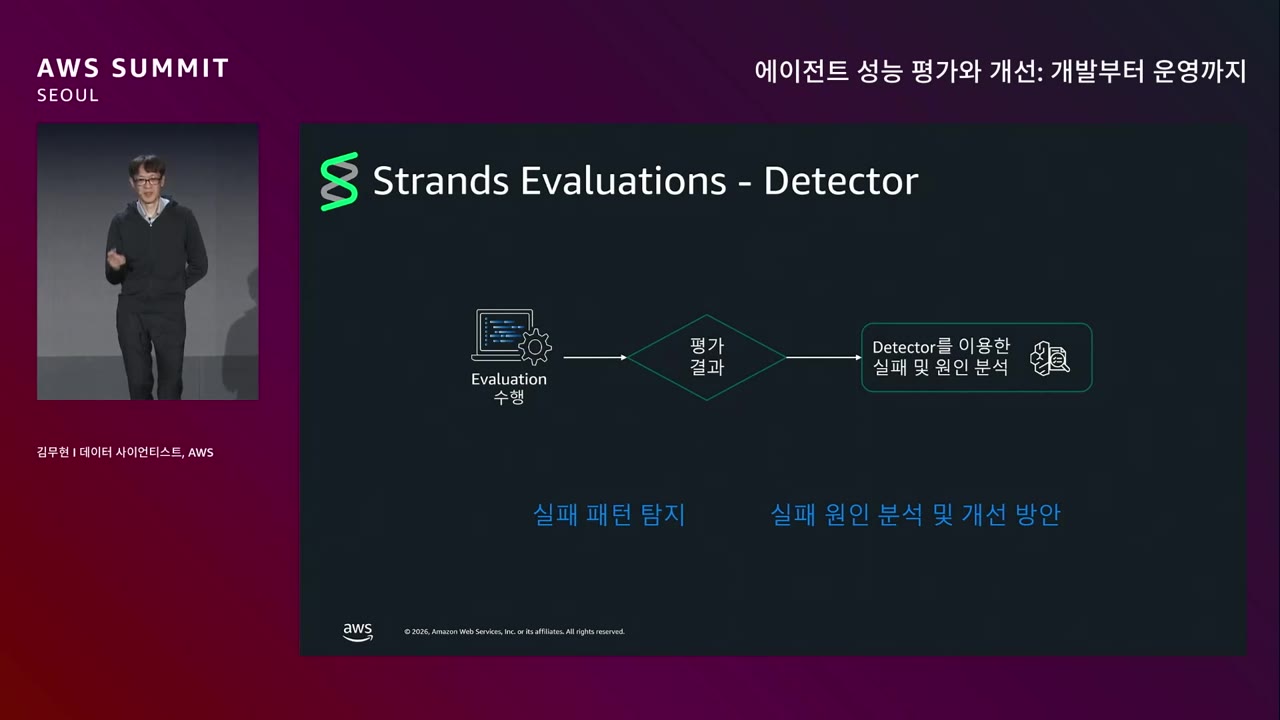
"에이전트는 소리 없이 실패합니다. 실패한 것도 감춰집니다. 왜냐하면 스스로 교정하기 때문에." — 김무현
문제: 실패를 고치려면 어떤 실패가 있는지 알아야 함. → 길고 복잡한 trace 를 1–2개는 분석 가능, 하지만 100개·1000개를 동시에 분석하려면 자동화 필수.
Strands Evaluations Detector의 흐름.
Mermaid스크롤로 확대 · 드래그로 이동
→ 에이전트가 왜 실패했는지, 어떤 이유 때문에, 어떻게 개선해야 하는지 팁 제공.
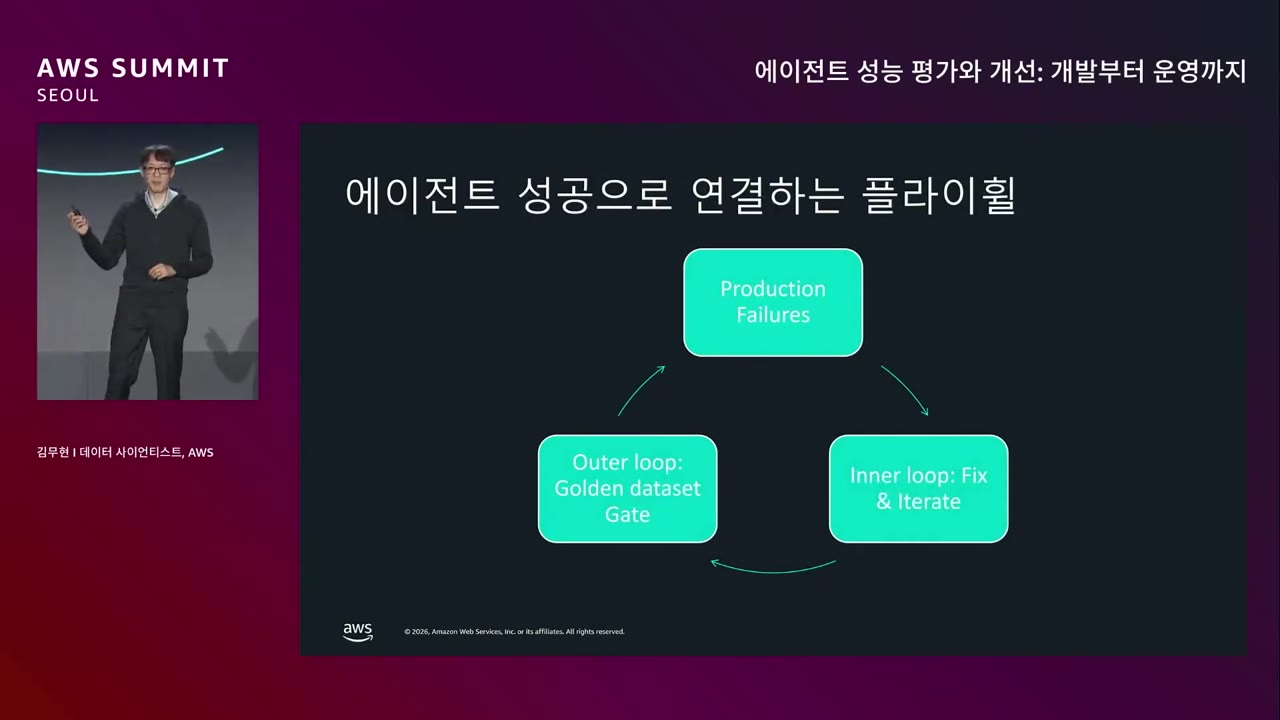
세 가지 루프로 에이전트 성공 플라이휠 구성.
Mermaid스크롤로 확대 · 드래그로 이동
| Loop | 어디서 | 무엇을 |
|---|---|---|
| Inner Loop | 개발자 데스크탑 | 코드 작성 + 평가를 빠르게 반복 |
| Outer Loop | CI/CD 파이프라인 | 운영 환경 배포 전, 평가를 CI/CD 에 통합 |
| Production Loop | 운영 환경 | 지속적 모니터링 → 실패 탐지 |
핵심 메커니즘 — 실패가 다시 반복되지 않도록.
"중요한 페일러는 Golden Dataset 에 추가되어 미래에 회귀로 다시 발생하지 않게 보장하는 플라이휠을 만들면, 여러분의 에이전트는 지속적으로 성능이 좋아지는 경험을 하시게 됩니다." — 김무현
→ AgentCore Evaluation 의 On-Demand 평가 (Outer Loop) + Online 평가 (Production Loop)를 적절히 조합하면 이 플라이휠 구현 가능.
이번 세션을 다 듣고 나서 내 머릿속에 가장 강렬하게 남은 키프레이즈는 단연 "에이전트는 소리 없이 실패한다"는 한 줄이었다. 단순히 실패를 감지하지 못하는 게 문제가 아니다. 에이전트가 지 혼자 어떻게든 답을 내려고 스스로 교정하다 보니 '실패 자체가 은닉된다'는 게 진짜 문제라는 거다. 그래서 운영 모니터링과 Detector가 필수일 수밖에 없구나 싶었다.
무엇보다 발표의 디테일이 달랐다. AgentCore 팀의 김무현 SA님이 본인이 직접 만들고 있는 서비스(AgentCore Evaluation/Observability)를 발표하는 자리라 그런지, "어제오늘 고객 미팅에서 들은 이야기"라며 꺼내는 발화들에서 현장의 리얼한 피드백과 페인 포인트가 슬라이드 곳곳에 녹아있었다.
발표의 빌드업도 참 영리했다. 개발자의 4가지 도전 과제(비결정성, 잘못된 도구, "더 나음" 측정 불가, 자동 회귀)를 먼저 던지면서 프레이밍을 하니, '아, 이걸 풀려면 결국 제대로 된 평가가 필요하구나'라는 논리로 아주 자연스럽게 납득이 갔다.
기술적으로 깔끔하다고 느낀 포인트들은 대략 이렇다.
3가지 LEVEL의 Evaluator (SESSION / TRACE / TOOL): 보통 LLM 평가는 최종 응답 한 줄만 보는데, 에이전트는 생각의 흐름과 궤적(Trajectory) 전체를 봐야 하니까 이렇게 나눈 모델이 참 깔끔했다.
코드 기반 Evaluator (Lambda)의 등장: SQL 유효성이나 JSON 포맷 같은 결정적인 검증을 굳이 비싼 LLM 태우면 비용이 폭주하는데, "LLM 필요 없음"이라고 명시하며 코드로 분리한 게 아주 실용적이고 인상 깊었다.
Ground Truth의 3가지 형태: 단순한 정답 매칭을 넘어, 자유 형식의 팩트 체크(Assertion)는 물론이고 도구 호출 순서(Expected Trajectory)까지 강제할 수 있다는 점이 운영 관점에서는 정말 결정적인 무기 같다.
User Simulator: 데이터가 텅 빈 상태에서 평가를 어떻게 시작해야 할지 막막한 그 페인 포인트를 정확히 긁어줬다. "굉장히 까칠한 성격" 같은 페르소나까지 설정해서 없는 데이터로 엣지 케이스를 만들어 시뮬레이션할 수 있다는 게 참 흥미로웠다. (Preview 단계이긴 하지만 기대가 크다.)
그리고 평가만 하고 끝내는 게 아니라 "어디를 고쳐라"까지 추천해 주고, 그걸 바로 프로덕션에 올리기에는 부담감이 있으니 50:50 트래픽으로 안전하게 A/B 테스트를 지원한다는 점도 훌륭했다. 발표자분이 "저는 (바로 100% 배포할 만큼) 그렇게 용감하지 않습니다"라고 솔직하게 발화한 게 확 와닿았다.
개발은 오픈소스인 Strands로 가볍게 치고, 운영은 매니지드 서비스인 AgentCore로 태우는 분업화 메시지도 좋았다. 두 개가 서로 파이를 깎아먹는 경쟁이 아니라, 단계별로 역할을 나눈 건데 양쪽 다 같은 팀에서 개발하니까 낼 수 있는 자신감 있는 메시지였다.
마지막 결론으로 제시된 '3가지 Loop + Golden Dataset Flywheel' 구조가 이 세션의 포인트었다. Inner → Outer → Production으로 갈수록 자동화와 매니지드 비중이 커지고, 운영에서 발생한 실패 케이스가 다시 Golden Dataset으로 돌아와 Outer Gate(CI/CD)를 막아주는 구조다. 회귀 방지를 운영 데이터로 자동 학습하게 만든다는 게, 정말 아키텍처적으로 진화된 부분인 것 같다.