AWS Summit Seoul 2026. 미래에셋증권이 AWS와 함께 금융 상품(ETF / 공모펀드 / 국내 채권) 정보 검색 정확도를 끌어올리기 위해 GraphRAG 기반 상품지식 DB를 구축한 PoC 여정. 발표는 강인호(AWS) → 이우람 수석(미래에셋) → 최창균 책임(미래에셋) → 이우람 수석(마무리) 순.

발표의 출발점은 한 줄짜리 문제 정의였다.
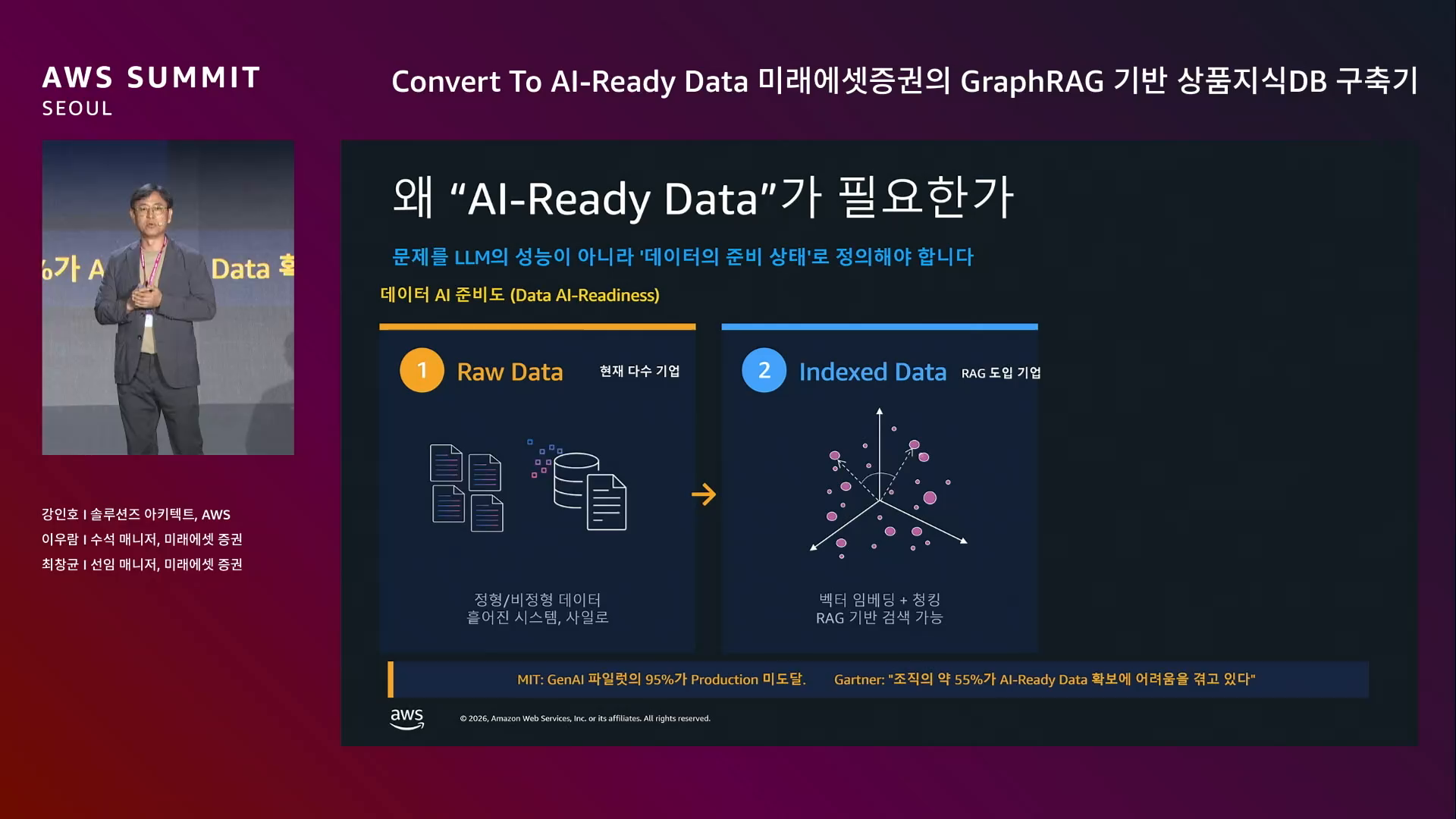
"AI가 데이터를 이해하기 위해서는, 데이터가 AI를 이해할 수 있도록 준비되어 있어야 한다."
MIT 조사에 따르면, GenAI를 파일럿에서 프로덕션으로 가지 못하는 비율이 95%. 강인호 SA는 이 95% 의 원인이 LLM 성능이 아니라 데이터의 준비 상태에 있다고 짚었다.
대다수 기업의 데이터는
벡터 임베딩 + 청킹 RAG는 "비슷한 문서를 찾기"는 하지만, 문서 간 관계, 데이터의 의미, 수치 정확성에서 약하다. 특히 수치 정확성이 중요한 금융에서는 실무 적용이 어렵다.
→ 해법은 시맨틱 레이어, 그 중심에 온톨로지.
온톨로지는 어렵게 들리지만, 본질은 인간이 가진 지식을 기계가 이해할 수 있는 형식으로 표현한 것. 더 쉽게는 지식에 대한 지도.
강인호 SA가 든 비유.
| 일반 RAG | Ontology + GraphRAG |
|---|---|
| 도서관의 일반 직원 | 도서관의 베테랑 사서 |
| 키워드 매칭으로 비슷한 책만 반환 | 데이터 간 관계를 머릿속에 갖고 있어, "성장주 ETF" 라고 하면 → 타이거 나스닥100 → 나스닥 추종 → 애플 보유 → IT 종목 식으로 맥락 추론 |


| 역할 | 담당자 |
|---|---|
| 프로젝트 리딩 + 도메인 온톨로지 + 그래프 설계 파이프라인 | 이우람 수석 (AI 인프라 파트) |
| Retrieval 엔진 + UI 구축 | 최창균 책임 |
| 비정형 데이터 파싱 + 데이터 엔지니어링 | 김석현 매니저 (팀 막내) |

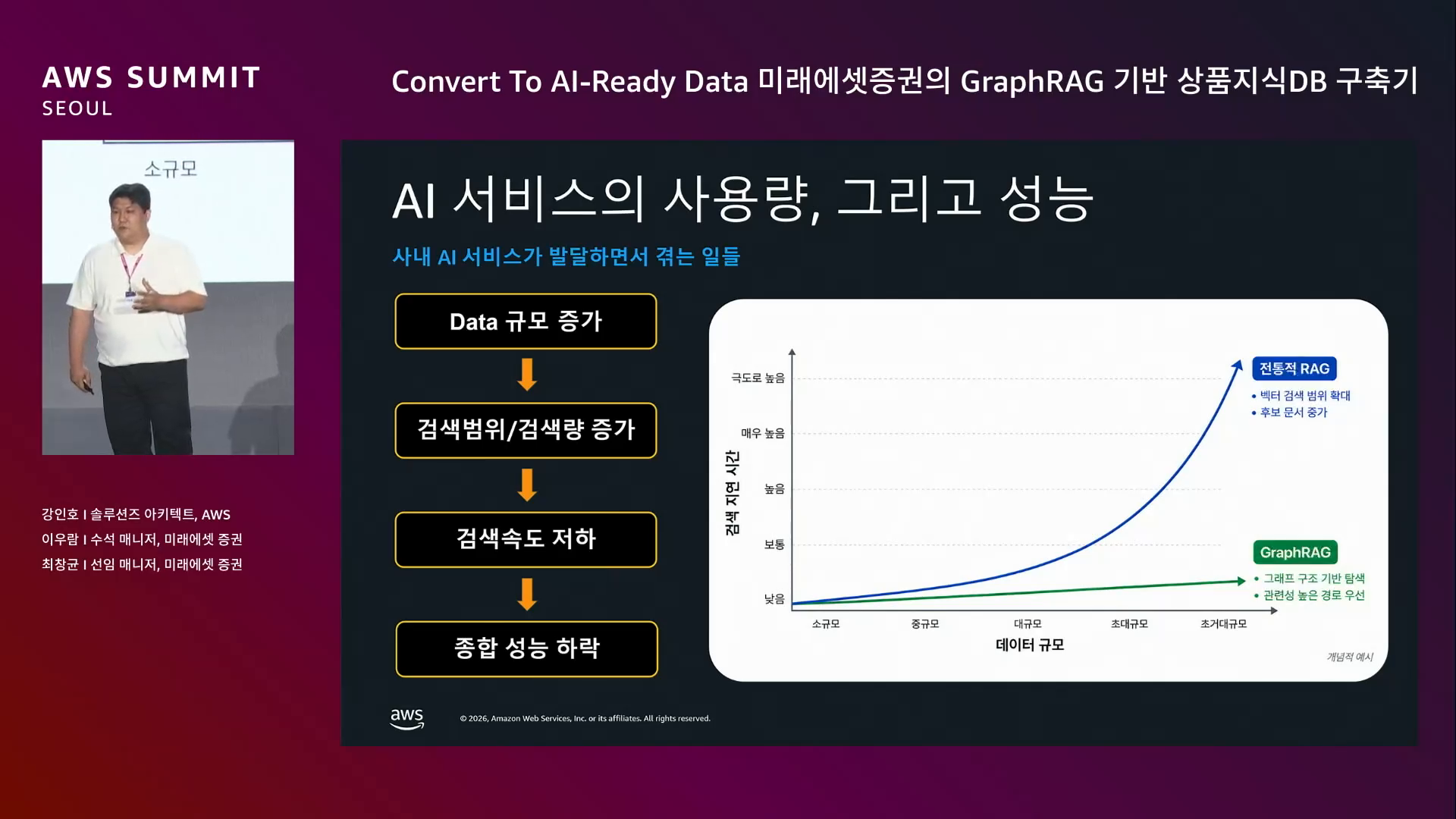
증권사도 다른 곳처럼 사내 AI 서비스를 구축·배포하고 있고, 그 핵심 기술이 RAG. 그런데 데이터 규모가 커지자
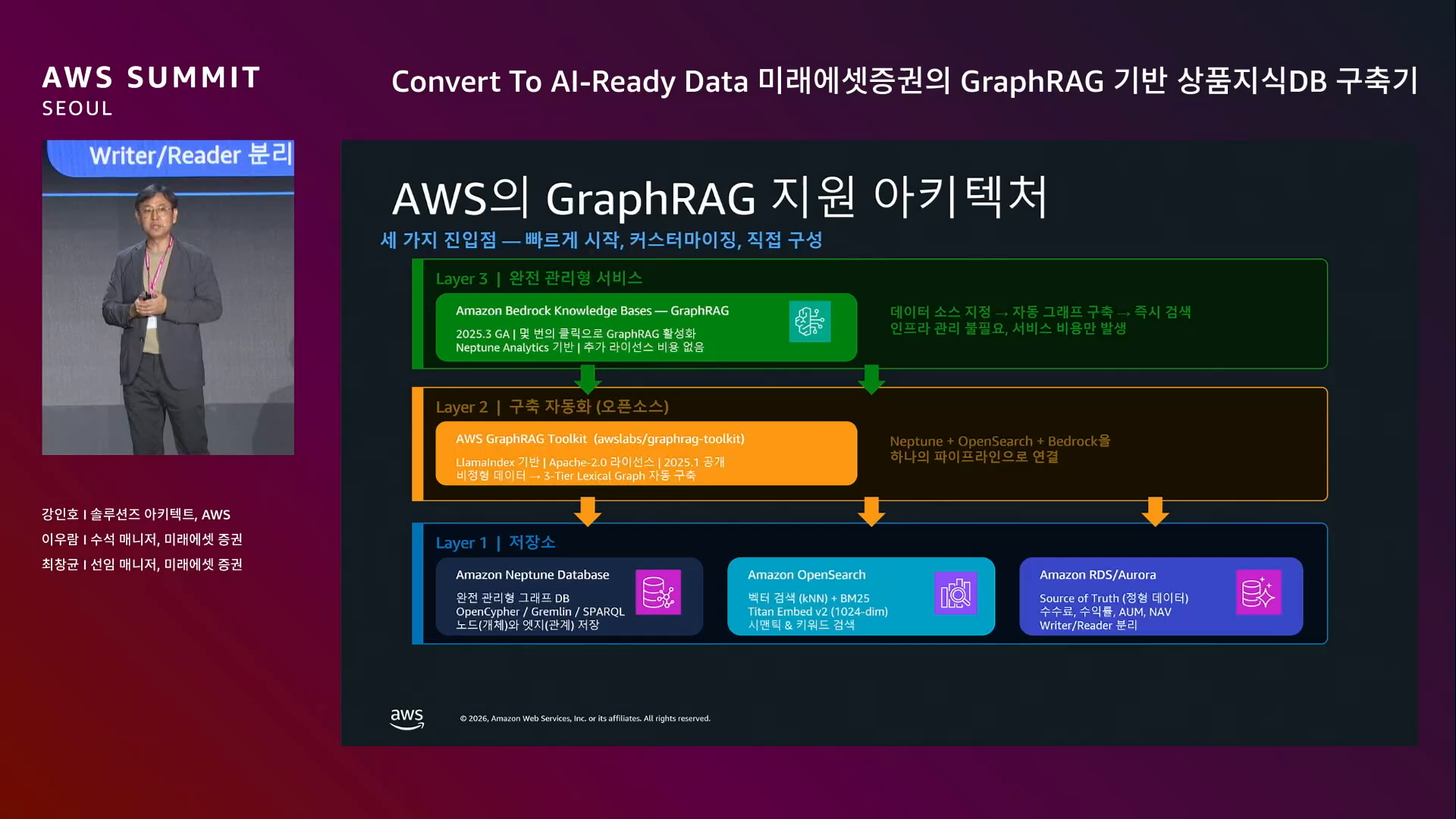
→ RAG의 다음 기술이 필요했고, GraphRAG를 찾게 됨.
GraphRAG의 강점.
목표: 사내 + 사외 마켓 데이터를 수집 → 정제·가공 → 지식 DB화 → 표준 검색 인터페이스 → 미래에셋 AI Agent 가 활용.

AWS의 실습 기반 PoC 가속 프로그램. 세 가지 장점.

많은 금융 데이터 중 왜 하필 상품 데이터?
선정된 3가지 상품 (EBA 특성상 너무 복잡한 상품 제외).

상품 검색의 페인 포인트는 사람마다 달랐다.
| 역할 | 니즈 |
|---|---|
| 고객센터 직원 | 유사어·카테고리 등 그룹 검색 |
| PB 직원 | 상품의 추천 사유 |
| 마케팅 부서 | 여러 조건을 한 번에, 대화하듯 텍스트로 |
| 상품관리 부서 | 매일 반복되는 동일 안내의 자동 응답 |

"아주 간단하죠."
EC2 위에 직접 소스코드를 짜서 구축. AWS의 핵심 서비스만 활용.
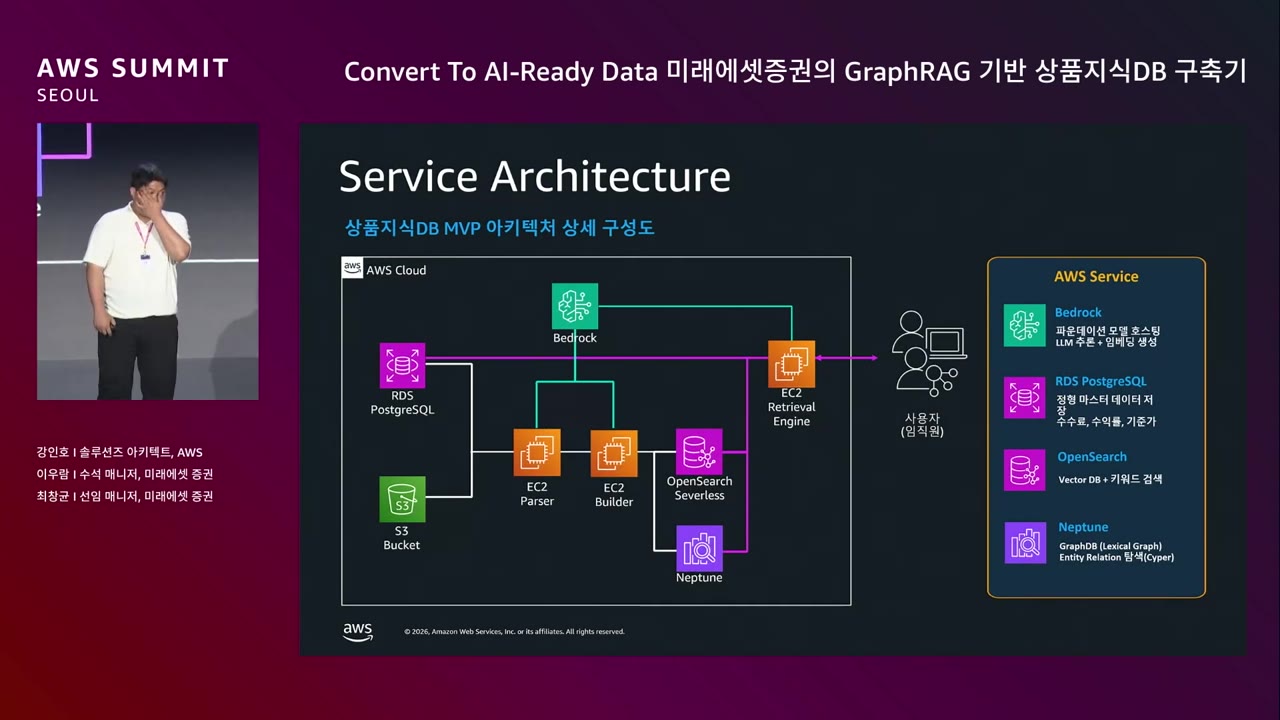
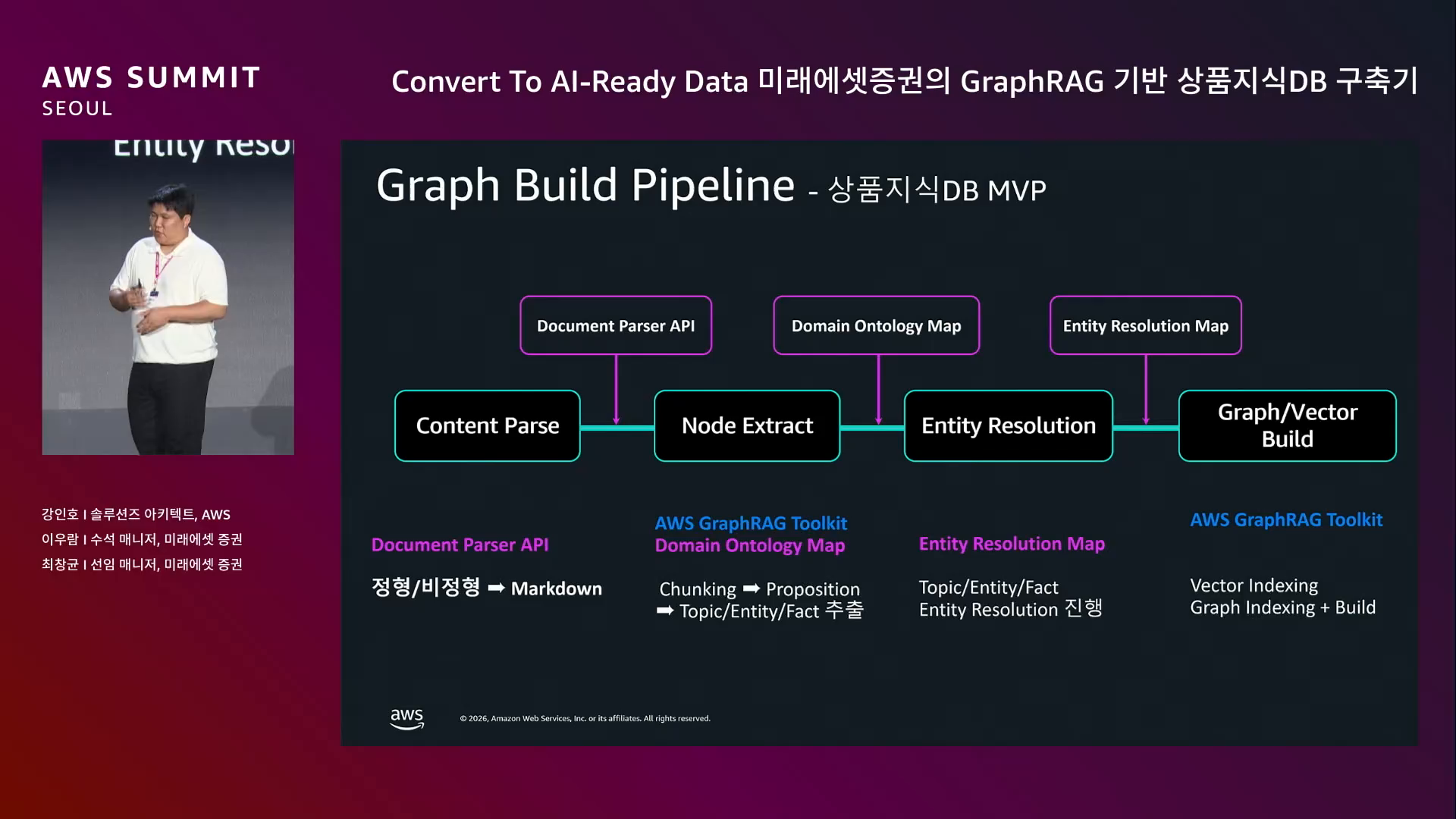
4단계로 구성.
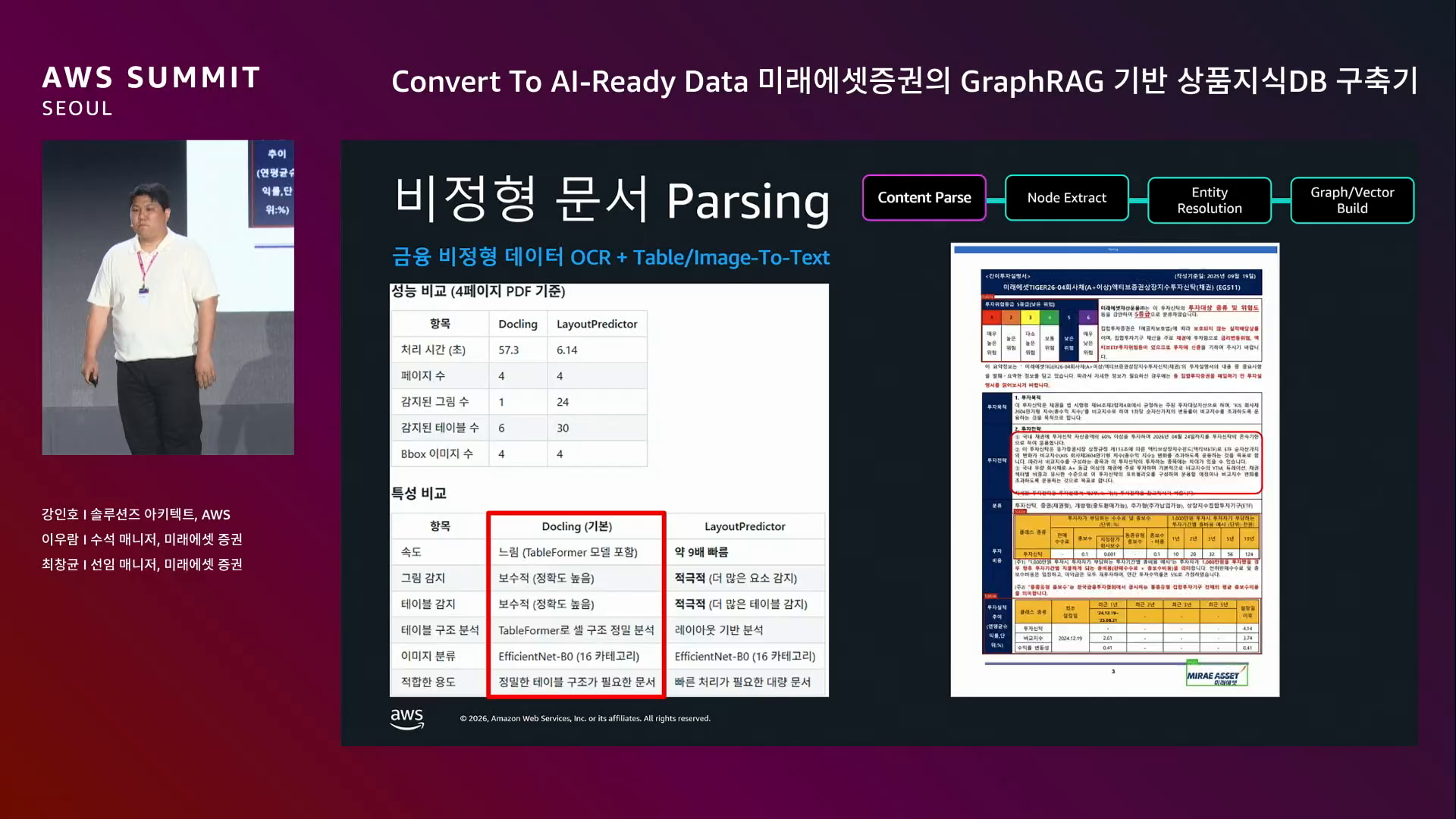
ETF 간이 투자설명서 샘플로 두 파서를 비교했다.
| 비교 항목 | Docling | 다른 패키지 |
|---|---|---|
| 처리 시간 | 길다 | 짧다 |
| 감지된 그림/테이블 수 | 적다 | 많다 |
"그런데도 우리는 Docling을 선택했다."
이유: 그림을 적게 감지하고 속도가 느리다는 건 보수적이고, 그만큼 정확도가 보장된다는 의미. 증권사에선 속도보다 신뢰 가능한 데이터가 더 중요하다.
도메인 온톨로지는 단번에 못 만든다. 4단계로 쌓아 올렸다.

ETF 온톨로지 초안 예시.
SM 자산운용사 → ETF 매니지 / ETF → 인덱스 추종 / ETF → 주식·채권·파생상품 보유 / ETF → 거래소 거래 / ETF → 요금·위험 보유

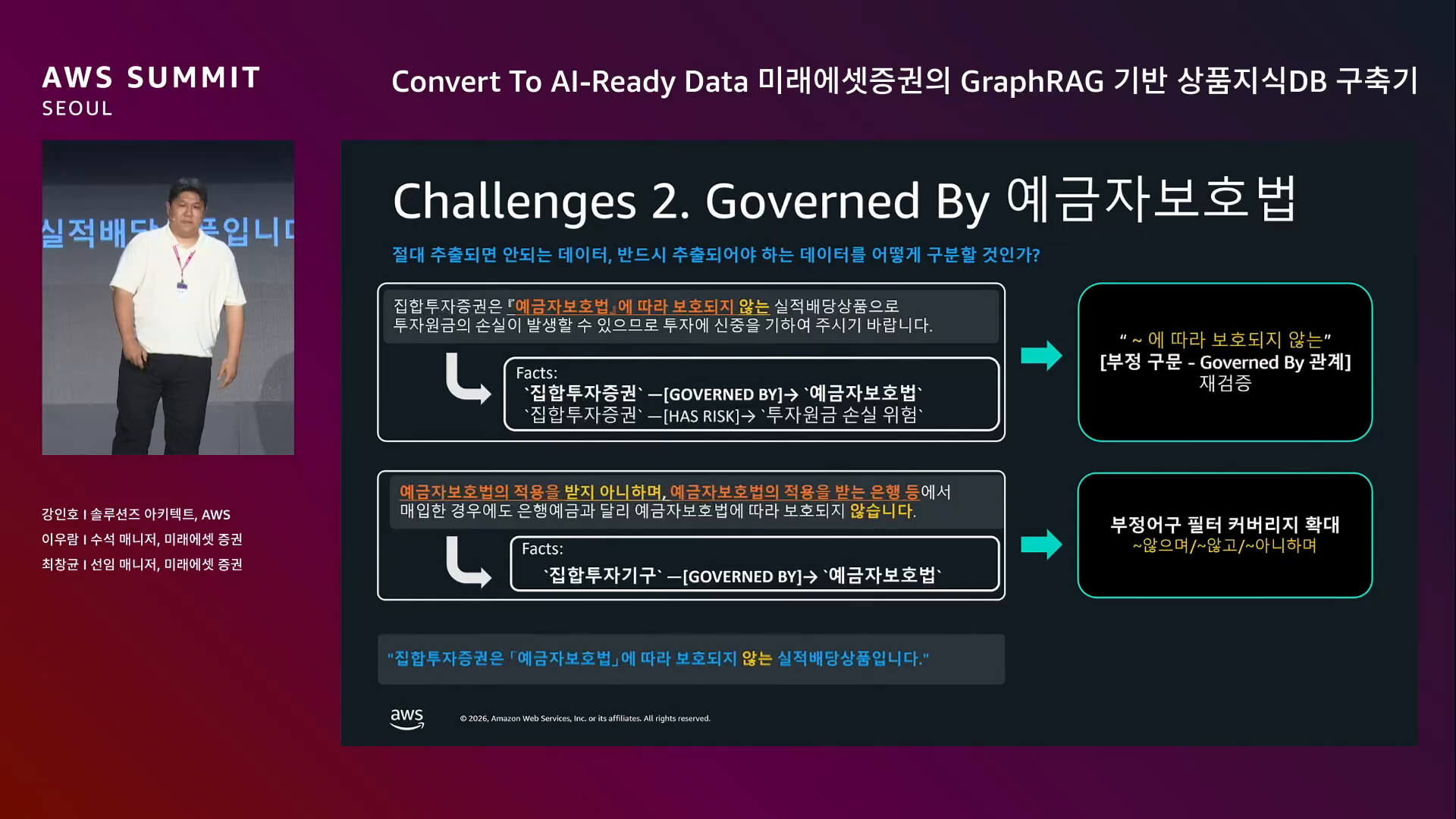
이 발표의 핵심 통찰 중 하나.
원문: "집합투자증권은 예금자보호법에 따라 적용되지 않는 실적 배당 상품입니다." 온톨로지 적용 후 추출된 Fact: "집합투자증권은 예금자보호법에 적용을 받습니다."
→ 부정 구문이 그대로 추출되지 않아 컴플라이언스 사고 직전.
해결.
Governed By 관계와 부정 구문 패턴을 결합하지만 핵심 시사점은 따로 있다. 결국 "ETF는 실적 배당 상품 → 예금자 보호 안 받음" 이라는 사실을 도메인 전문가가 알고 있어야 검증이 가능하다. Human-in-the-loop가 GraphRAG에 반드시 필요하다.
Document → Chunk → Node 흐름 후, Chunk A/B/C 에서 추출된 노드가 같은 의미인데도 분리되면 그래프가 커질수록 연결 안 되는 엔티티가 늘고, 종합 성능에 큰 영향.
업계 벤치마크: ER 적용/미적용 차이로 멀티홉 질문 정확도 20~40% 향상.

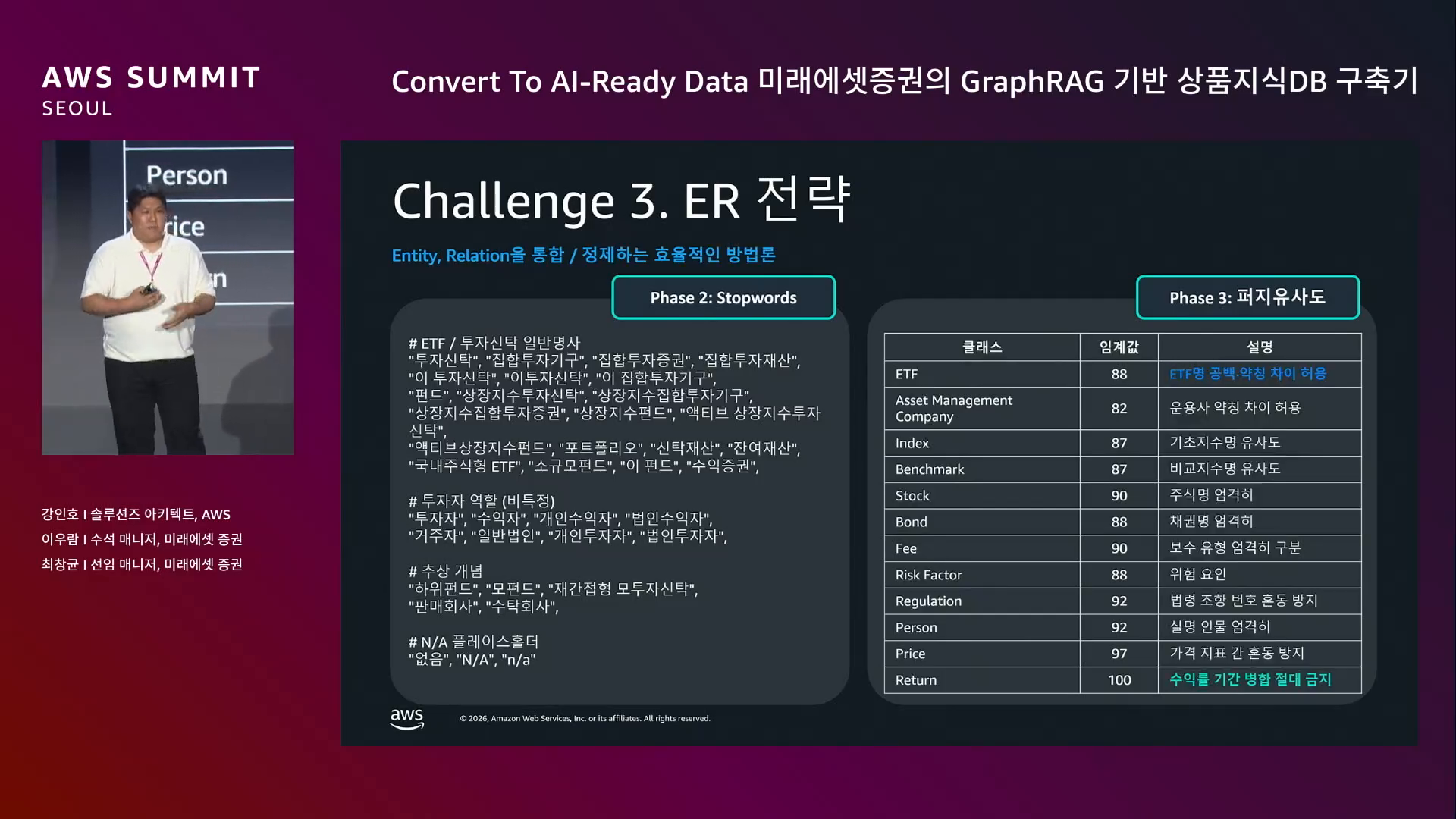
ER 4단계.
세부 케이스 두 가지.
| 케이스 | 처리 |
|---|---|
| Stop-words (대명사) | "이 투자 신탁은", "이 종목은", "이 집합투자증권은" → 실제 의미 없는 엔티티 → Stop-words 필터로 제거 |
| Fuzzy Matching 임계값 | 기본 80%로 시작 → ETF명은 약측 허용 (병합 잘 됨), 수익률 1일 / 3일 / 5일 같은 중요 정보는 임계값 미달로 다 병합되는 문제 → 엔티티별 임계값 분리 |
"어떻게 보면 제일 중요한 부분."
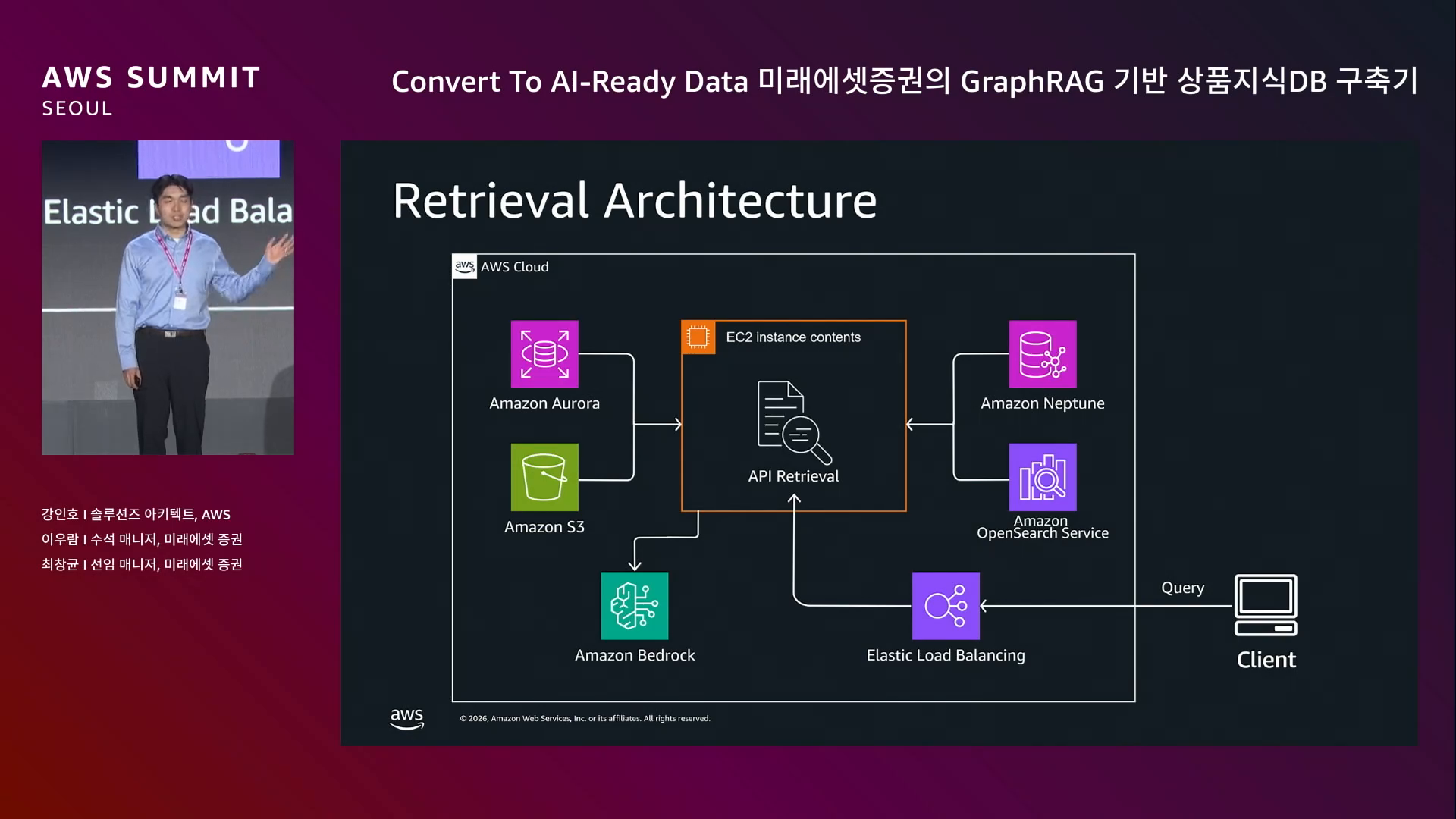
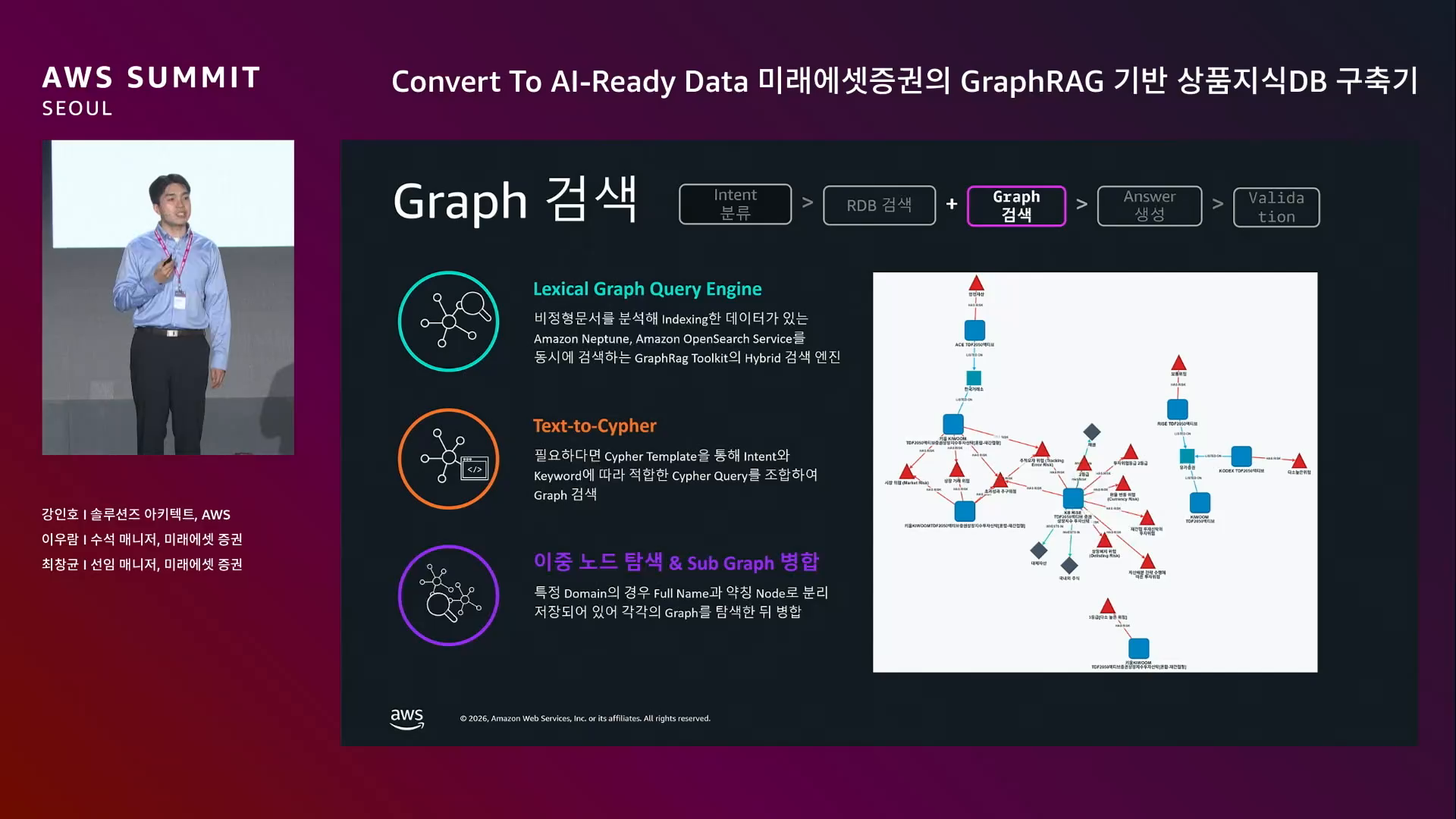
전체 흐름.
사용자 질의 → Intent 분류 → RDB 검색 / Graph 검색 → Answer 생성 → Validation → 사용자
모든 에이전트는 AWS Strands Agent SDK로 구현. 각 단계가 독립 에이전트.
"이때는 무조건적으로 LLM을 사용하지 않았다."

"처음부터 SQL을 생성해달라고 하면, 잘못된 컬럼 참조나 잘못된 JOIN 이 발생할 수 있다."
해결: LLM에는 SQL의 핵심 요소만 추출시키고, 실제 SQL 문자열은 Python 코드로 안전하게 조립.

"절대 할루시네이션이 없어야 한다."
두 가지 원칙.
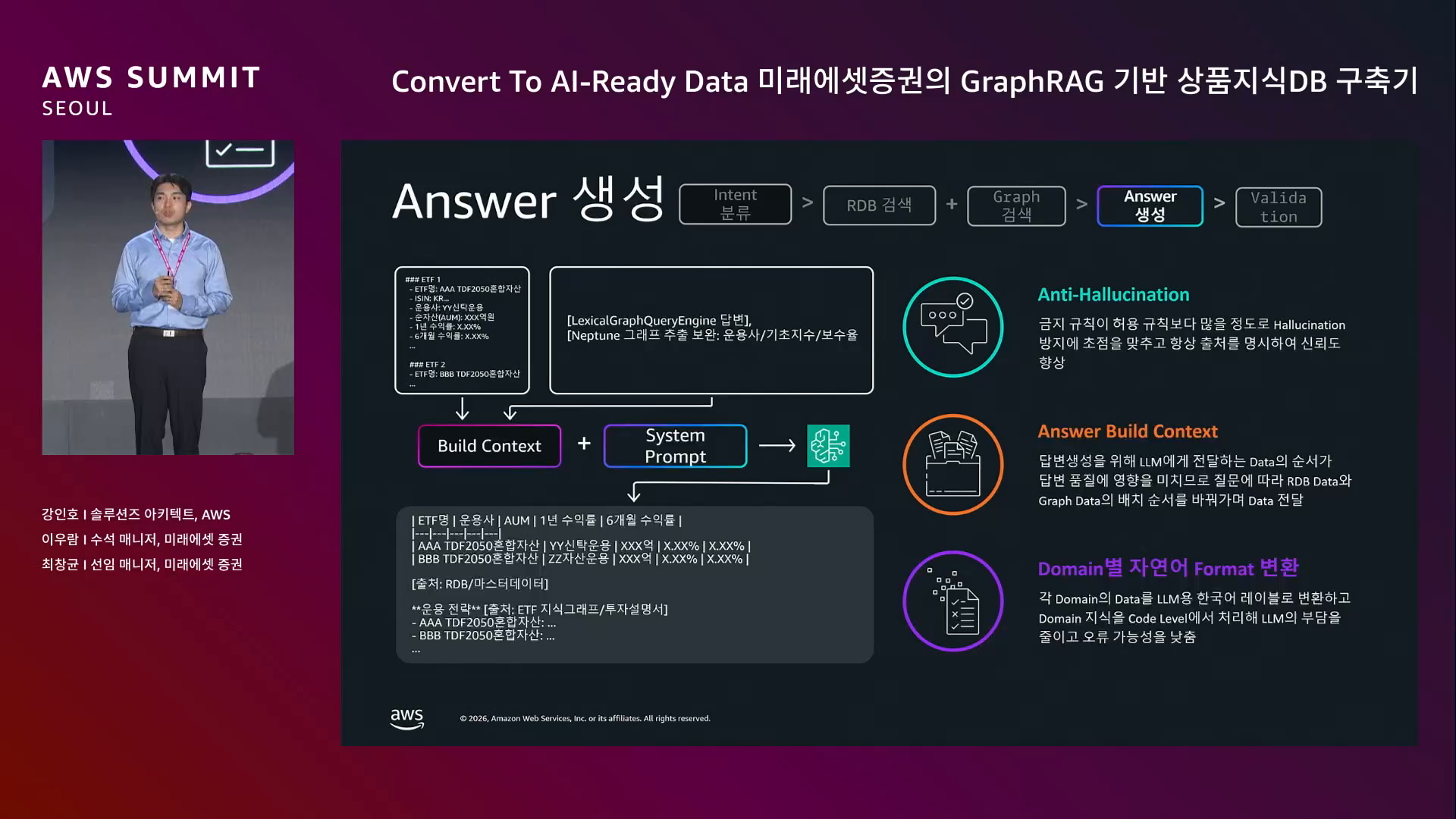
검증 항목 3개에 대해 체크 후 사용자에게 답변 노출.

데모 화면은 두 패널로 분리.
사용자 패널 — 자연어 질의 입력 → 진행 상태 표시 → 표 / 특징 / 운용 전략 비교 → 출처 명시 → 요약 + 그래프 시각화.
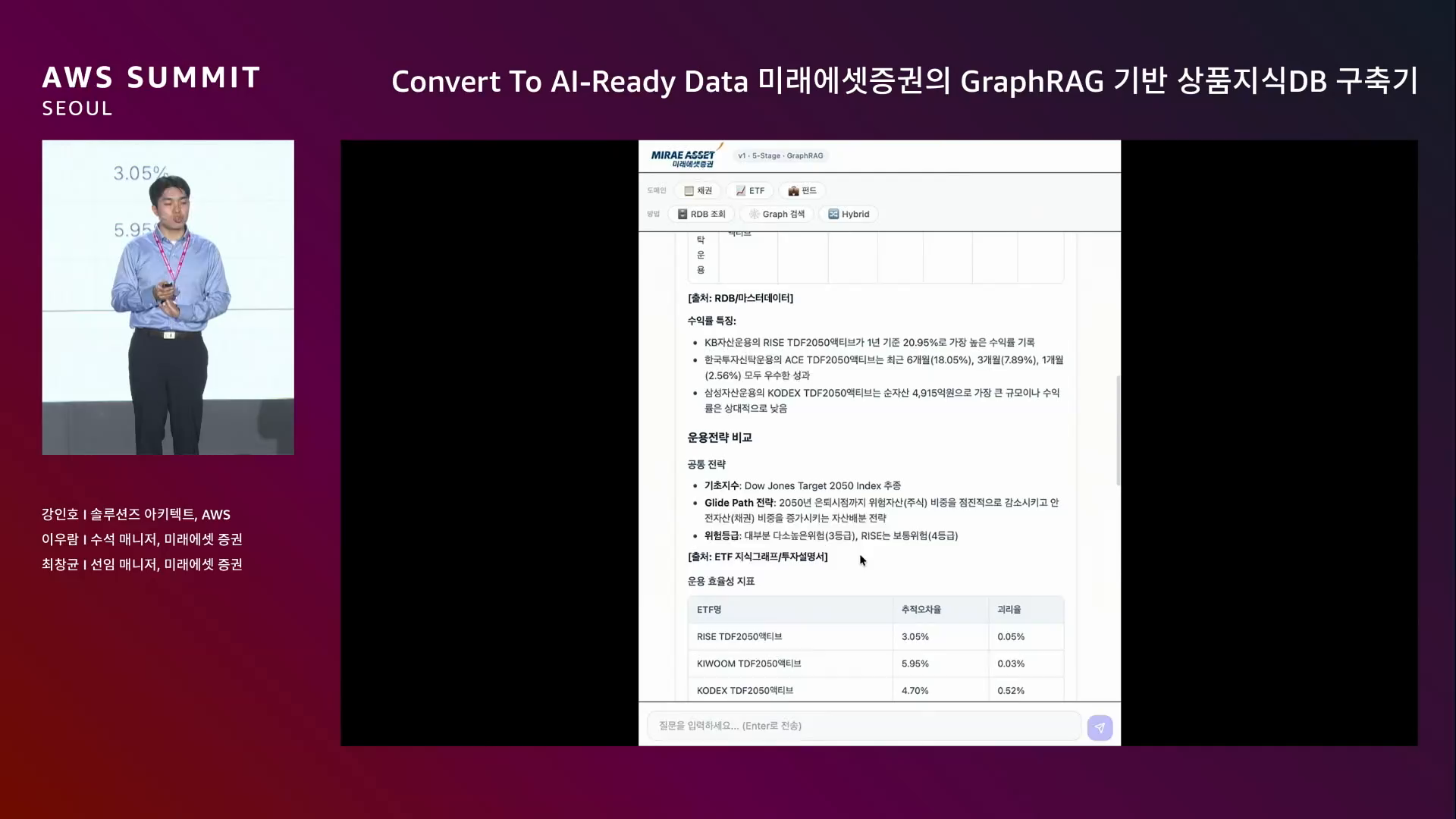
관리자 패널 — 실제 그래프 DB 구조, Intent 분석 결과 + 검색한 DB와 이유, Text-to-SQL 결과, Graph 검색 시 노드/엣지, 사용된 LLM 모델 + 답변 길이, Validation 점수까지 전체 파이프라인을 시각화.
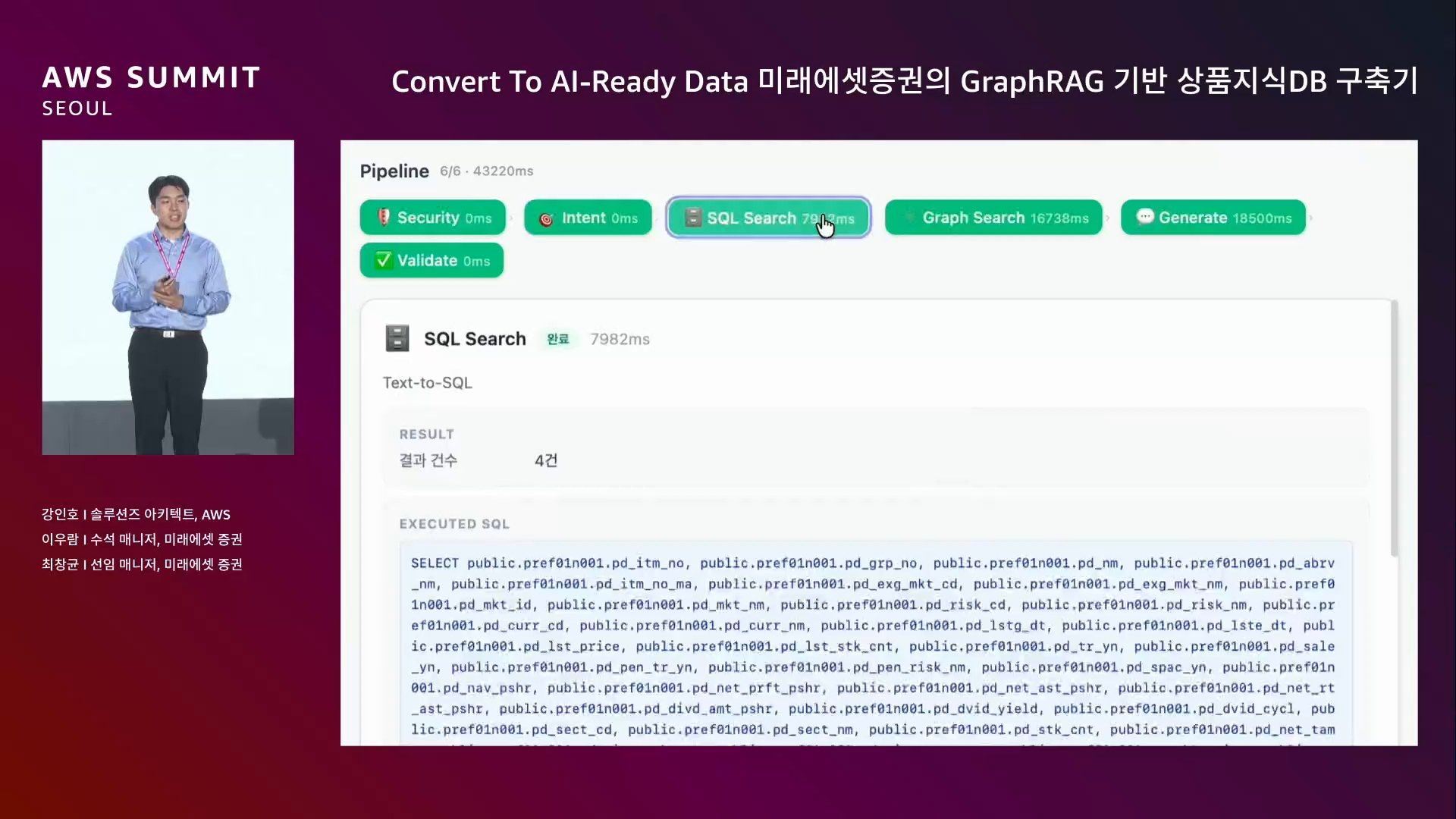
"본의 아니게 두 번 등장하게 됐다." (웃음)


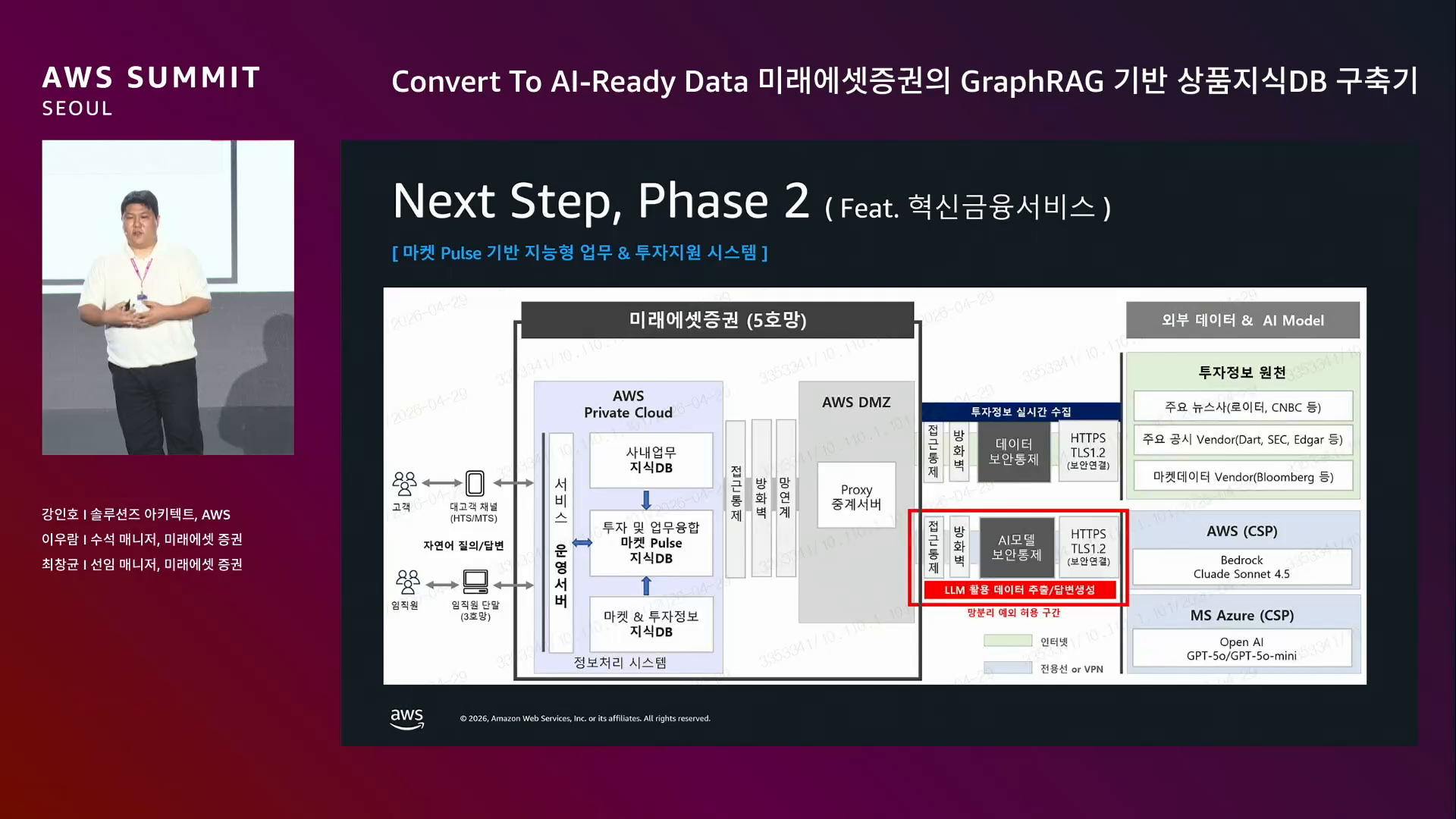
혁신금융 서비스 지정 (2026년 3월 중순) SOTA LLM (Bedrock) 을 내부망 서비스에서 쓸 수 있는 구조 확보. 현재 이 스킴 위에서 구축 진행 중.

업무 지식 + 투자 지식 융합 → 외부 데이터를 SOTA 모델로 지식화 → 고객 / 임직원에게 제공.
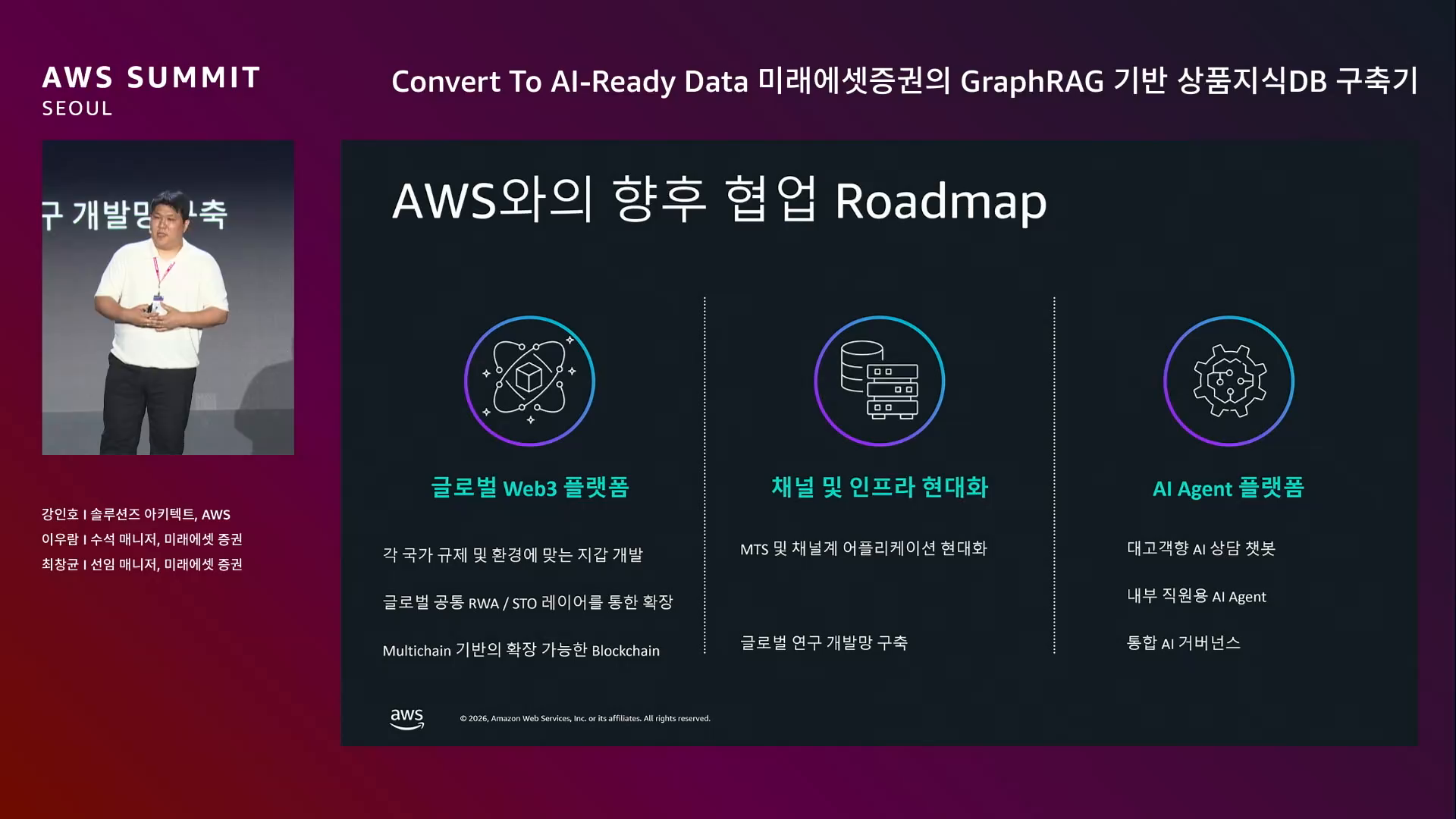
세 갈래.
이 세션이 처음부터 끝까지 한 줄로 관통하고 있다고 느꼈던 키프레이즈는 강인호 SA님이 던진 "AI가 데이터를 이해하려면, 데이터가 AI를 이해할 수 있도록 준비되어 있어야 한다"였다. LLM을 더 잘 튜닝하자는 게 아니라 결국 데이터의 준비도(AI-Ready Data)가 진짜 병목이라는 메시지. MIT의 "95%가 파일럿에서 프로덕션 못 간다" 통계를 끌어와 받쳐주니까 더 묵직하게 다가왔다.
발표 구성도 영리했다. AWS가 큰 그림을 깔고 → 미래에셋이 실제 PoC 여정을 보여주고 → 다시 AWS·미래에셋 협업 로드맵으로 닫는 흐름이었는데, "실제로 만들어 본 사람의 디테일"이 정말 많이 나왔다. 이우람 수석님이 "그런데도 우리는 Docling을 선택했다" 같은 결정 사유를 솔직하게 풀어줘서, 단순 제품 소개가 아니라 실전 의사결정 노트를 듣는 느낌이었다.
기술적으로 와닿은 포인트들을 정리해보면 이렇다.
상품 데이터부터 시작한 선택의 영리함: 금융 데이터가 한둘이 아닌데 왜 상품이냐는 질문에 — Source of Truth 원장 데이터 보유 + 임직원 모두가 쓰는 범용성 + 파트원의 도메인 지식, 세 가지 축이 다 충족되는 영역이었다는 설명이 굉장히 설득력 있었다.
Governed By 라는 컴플라이언스 관계를 그래프 일급 시민으로 둔 점: "집합투자증권은 예금자보호법에 적용되지 않는다" 가 부정 구문 처리 미흡으로 "적용을 받습니다" 로 추출돼 사고 직전까지 갔던 사례. 단순 NLP 이슈를 넘어, 금융 도메인에선 부정 구문 자체가 컴플라이언스의 본질이라는 걸 그래프 관계로 끌어올린 게 인상 깊었다.
Human-in-the-loop의 필요성을 회피하지 않은 자세: "결국 ETF가 실적 배당 상품이라는 걸 도메인 전문가가 알고 있어야 검증된다." 라고 솔직하게 인정한 부분이 좋았다. AI 만능론을 외치지 않고 SME가 들어와야 한다는 걸 발표 한가운데에 박아두는 게 진짜 운영을 해본 팀의 자세 같았다.
"무조건 LLM 쓰지 않는다" 원칙: 최창균 책임님이 Intent 분류 단계에서 LLM을 안 쓴다고 못 박은 부분이 매우 실용적이었다. 키워드 매칭이나 Semantic Router로 해결되는 건 LLM을 안 부르는 게 비용·지연·할루시네이션 세 가지를 동시에 잡는다는 사실. 발표에서 이걸 강조한 게 아주 와닿았다.
Text-to-SQL의 안전 패턴: LLM에 SQL을 통째로 짜라고 하면 잘못된 컬럼·JOIN이 나오니까, LLM에는 핵심 요소만 추출시키고 SQL 문자열은 Python으로 조립한다는 패턴. 도메인별로 프롬프트도 분리해 운영하는 디테일까지 — 흔히 쓰는 Text-to-SQL을 안전하게 운영하기 위한 진짜 노하우였다.
Anti-Hallucination을 "금지를 많이"로 푼 접근: 출처(노드·엣지) 명시 의무 + "임의 생성·추정·추측 금지" 를 프롬프트에 명시적으로 박아두는 정책. 허용을 늘리기보단 금지를 늘리는 쪽이 운영 환경에선 훨씬 안전하다는 발화가 기억에 남는다.
데모의 관리자 패널: Intent / Text-to-SQL / Graph 검색 노드·엣지 / 사용 LLM·답변 길이 / Validation 점수까지 모든 단계를 가시화해 둔 게 인상적이었다. 사용자 패널은 결과만 보여주지만, 운영팀이 디버깅·튜닝·감사용으로 쓸 관리자 패널을 같은 화면 안에 분리해 둔 게 진짜 운영을 염두에 둔 설계였다.
Docling 선택 이유 — "느리지만 정확": 그림을 적게 감지하고 처리 시간이 길다는 건 보수적이라는 뜻이고, 그만큼 정확도가 보장된다는 거다. 증권사는 속도보다 신뢰가 우선이라는 자기 도메인에 대한 명확한 인식이 보였다.
마지막으로 가장 크게 와닿았던 메시지는 — 혁신금융 서비스 지정 + Bedrock 내부망 활용으로 SOTA LLM을 규제 산업에서 합법적·현실적으로 쓸 수 있는 길을 열었다는 점이었다. 기술이 아무리 좋아도 규제와 보안이 못 따라가면 금융권에선 못 쓰는데, 이걸 풀어내는 정공법을 정확히 짚어 보여준 사례였던 것 같다.
https://summitseoul.awslivestream.com/sel-ind206/live/