올해부터는 메타광고도 돌리고 나름 서비스가 성장하면서 트래픽과 약간의 매출이 늘어났고, AWS 한 대로는 잘 버티다가도 간혹 서비스 접속이 안 될 때가 있었다. 또 최근에는 이에 따라 저번 개모임 발표 때 언급했던 것처럼 악성 유저나 봇이 공격을 보내서 프론트 서버가 꺼지는 문제도 있어 우리 개발팀에서는 일단 급한 불이라도 끌 수 있도록 이를 간단하게라도 해결해야 하는 문제가 시급했었다.
우리 서비스는 그동안 프론트엔드 Next.js의 인스턴스는 단일 AWS의 단일 인스턴스로 운영해왔다. 일반적인 상황에서는 괜찮았지만, 가끔 Node.js가 인스턴스 메모리 이슈로 죽거나 빌드 후 재시작할 때 서비스가 중단되는 문제가 있었다.
아마 일전 개발자 분들은 일반적인 PM2를 사용해 프로세스를 클러스터 모드(인스턴스 크기 보통 medium 메모리 4GB 이상에서 권장되는 부분으로) 두개 이상의 프로세스를 붙여 reload하는 식으로 low한 레벨의 무중단 배포를 사용하는 방식으로 계속 사용해 왔었다. 그러나 근본적인 해결책은 아니었다.
그러다 일전의 창희님이 전에 회사에서의 경험을 말씀해주신 부분을 떠올랐고, 인스턴스끼리를 프로세스끼리 묶어 레이스 하면서 움직이는 구조로 만들었다는 내용이 생각났다. 마침 우리는 투자사를 통해 구글한테 GCP 크레딧을 꽤 많이 가지고 있고 낭비하고 있으니 route53을 통해 aws 인스턴스와 GCP 인스턴스 두개를 엮자라는 이야기가 나와서 내가 드디어 이 부분을 만지게 되었다.
따라서 AWS 말고도 GCP(Google Cloud Platform)에도 현재 aws와 비슷하게 돌고 있는 인스턴스 사양을 빌리게 되었다. 일전에도 크레딧을 활용한다고 인스턴스와 고정아이피를 엮고 기초적인 nginx와 설정들을 하였지만 늘 느끼는 점은 기본적으로 처음 서버를 세팅할때에는 oauth 방식으로 접근해서 그런지 GCP의 세팅은 늘 너무 간단하게 느껴진다. 따라서 빠른 세팅이 가능했다.
그렇게 GCP 인스턴스도 AWS와 동일하게 구성했다. 하지만 이제 진짜 문제는 시작되었다.
"두 서버를 어떻게 연결할 것인가?"
처음에는 단순히 A 레코드를 2개 등록하면 되는 줄 알았다. 하지만 DNS 라운드 로빈은 서버 상태 확인도 안 되고, 분배도 균일하지 않았다.
그래서 다른 방법을 찾아봤다.
결과적으로 AWS Route53을 통해 AWS와 GCP 두 서버에 50:50 비율로 가중치를 주는 방식을 선택했다. 완전한 failover 기능을 구현하지는 못했지만, Route53의 헬스 체크 기능을 활용하여 한 서버가 다운되면 자동으로 다른 서버로 트래픽을 보내는 방식을 구현했다. 실험 결과 Route53이 꽤 똑똑하게 작동해서 한 서버가 셧다운되면 약간의 딜레이는 있지만 꽤 자연스럽게 다른 서버로 트래픽을 전환했다.

TypeScriptRoute53 가중치 기반 라우팅을 통한 카나리 배포 ┌─────────────────┐ │ Route53 │ │ 가중치 라우팅 │ └────────┬────────┘ │ ┌──────────────┴──────────────┐ │ │ ┌───────▼───────┐ ┌───────▼───────┐ │ AWS 서버 │ │ GCP 서버 │ │ (현재 버전) │ │ (새 버전) │ └───────────────┘ └───────────────┘ 가중치: 90% 가중치: 10%
처음에는 GCP에 헬스 체크 스크립트를 만들어서 AWS 상태를 확인한 후, 다운되면 도메인 DNS를 변경하는 방식을 생각했다. 하지만 DNS 전파 시간이 있어 즉각적인 대응이 어려웠다.
다음으로 생각한 것은 두 서버 모두에 Nginx를 설정하고, 각각 자신과 상대방을 모니터링하는 방식이었다.
PLAIN# AWS Nginx 설정 (초기 시도) upstream front { server 127.0.0.1:3000; } server { listen 80 default_server; server_name .co.kr; location / { proxy_pass <http://front>; proxy_http_version 1.1; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } }
하지만 이 방식도 실시간 감지와 전환이 쉽지 않았다. 고민 끝에 각 서버에 동일한 애플리케이션을 띄워놓고, 둘 다 도메인으로 연결한 뒤, Route53의 헬스 체커가 알아서 트래픽을 분산시키는 방식을 채택했다.
이제 두 서버가 모두 같은 도메인으로 서비스되다 보니, 어떤 요청이 어디서 처리되는지 구분하기 어려웠다. 이를 해결하기 위해 각 서버에서 응답 헤더에 서버 ID를 추가했다.
PLAIN# AWS Nginx 설정 location / { add_header X-Server-ID "AWS-Server" always; proxy_pass_header X-Server-ID; proxy_pass <http://front>; proxy_http_version 1.1; ... }
PLAIN# GCP Nginx 설정 location / { add_header X-Server-ID "GCP-Server" always; proxy_pass_header X-Server-ID; proxy_pass <http://front>; proxy_http_version 1.1; ... }
헤더 추가 덕분에 개발자 도구에서 응답 헤더를 확인하면 어느 서버에서 응답했는지 바로 알 수 있게 되었다. 디버깅이 한결 수월해졌다.
또 하나의 문제는 SSL 인증서였다. AWS에서 Let's Encrypt로 발급받은 인증서를 GCP에도 적용해야 했다.
두 서버 모두 각각의 인증서를 사용라면서 공유하게 되었고, 갱신 스크립트도 양쪽에 설정했다. 다행히 Let's Encrypt는 여러 서버에서 같은 도메인의 인증서를 사용하는 것을 허용한다. 이 부분에서는 솔직히 인증과정에서 조금 무모하게 운빨을 맡겼다.(어릴 때 메이플 주문작하는 것 같았다.) 각각의 다른 IP를 동시에 인증받아야하므로 가중 서버 비율을 50대 50을 두고 진행했다.

우리 서비스는 메인 도메인 외에도 여러 서브도메인과 예전 도메인들이 있었다. 이들을 모두 메인 도메인으로 리다이렉트하는 설정도 필요했다.
PLAIN# HTTP 서버 블록 server { listen 80 default; server_name 소유하고 있는 도에민들; location /.well-known/acme-challenge/ { allow all; root /var/www/html; try_files $uri =404; } location / { return 301 https://.co.kr$request_uri; } } # HTTPS 서버 블록 - 서브도메인 리다이렉트 server { listen 443 ssl http2; server_name 소유하고 있는 도에민들; ssl_certificate /etc/letsencrypt/live/.co.kr/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/.co.kr/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; location / { return 301 https://.co.kr$request_uri; } }
이 설정을 AWS와 GCP 양쪽에 모두 적용했다. 덕분에 어떤 도메인으로 접속하든 항상 메인 도메인으로 리다이렉트되었다.
이제 두 서버를 모니터링하고 문제가 발생하면 알림을 받을 수 있는 시스템이 필요했다. 사실 인프라 증설 전에 창희님이 만들어 주신 파이썬 헬스 체커가 있었는데, 이는 서버가 새벽에 꺼지면 알림이라도 받을 수 있게 하는 기본적인 모니터링 도구였다. 이를 기반으로 더 발전된 형태의 모니터링 시스템을 구상했다.
현재는 간단한 쉘 스크립트로 상태 확인을 하고 있지만, 아직 알림톡 기능은 구현 예정 단계이다.
Bash#!/bin/bash # server_monitor.sh SERVER_URL="<https://.co.kr>" WEBHOOK_URL="<https://hooks.slack.com/services/XXXXXXX/XXXXXXX/XXXXXXXXXXXXXXXX>" STATUS=$(curl -s -o /dev/null -w "%{http_code}" $SERVER_URL) if [ "$STATUS" != "200" ]; then MESSAGE="서버 응답 오류: $STATUS - $(date)" curl -X POST -H 'Content-type: application/json' --data "{\\\\\\\\"text\\\\\\\\":\\\\\\\\"$MESSAGE\\\\\\\\"}" $WEBHOOK_URL # 서버 재시작 시도 sudo systemctl restart nginx sudo pm2 restart all fi
이 스크립트를 5분마다 실행하도록 cron에 등록했고 현재는 문제가 생기면 슬랙이 걸려서 날라온다. 나중에는 이것도 백오피스 시스템에 통합하고, 알림톡으로 상태 알림이 오도록 개선할 예정이지만, 지금은 급한 불부터 끄는 데 집중했다.
실제로 이 구성을 적용한 후, 서비스 안정성이 크게 향상되었다. 한쪽 서버가 다운되더라도 다른 서버가 요청을 처리할 수 있게 되었고, 서버 유지보수나 업데이트 시에도 서비스 중단 없이 작업할 수 있게 되었다.
가장 기억에 남는 순간은 AWS 서버에서 Node.js 메모리 이슈로 서버가 다운되었을 때였다. 이전 같으면 새벽에 누군가가 긴급하게 대응해야 했겠지만, 이번에는 GCP 서버가 트래픽을 모두 처리했고, 아침에 여유롭게 확인해서 AWS 서버를 재시작할 수 있을 정도는 되었다.
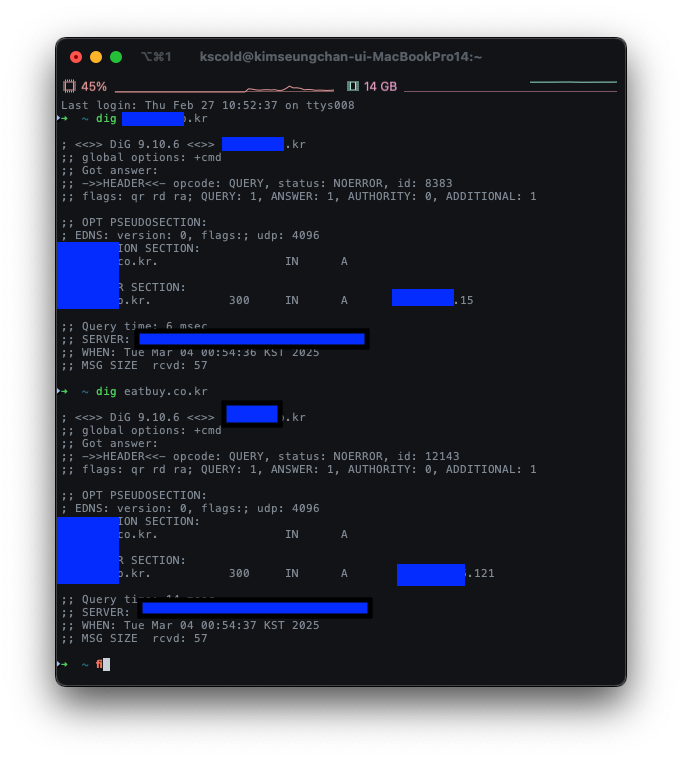
dig로 요청 시 나름 잘 분기되는 모습
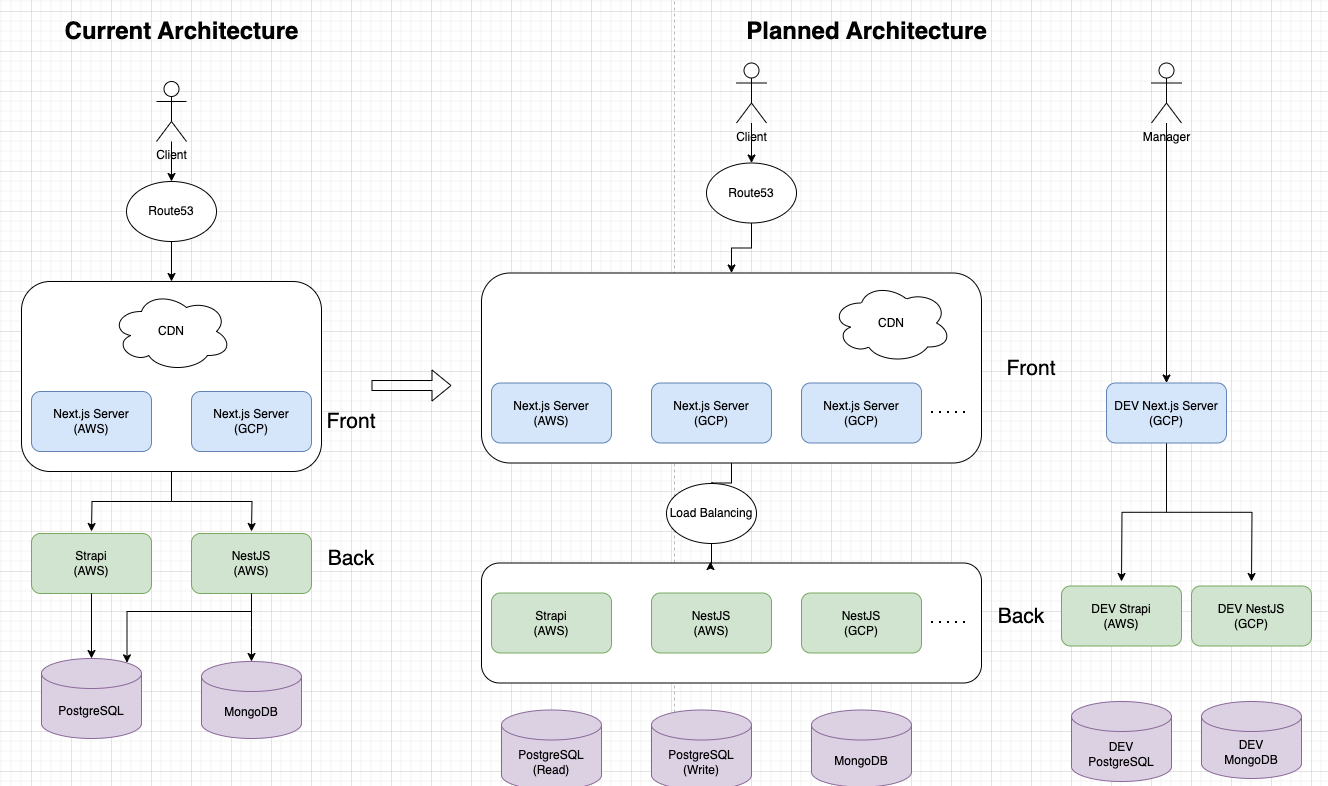
앞으로의 우리 서비스 인프라 방향성…
최근에 스스로 좀 나태해져서 현재까지의 지식기반으로 많이 백엔드 개발을 진행하였다. 이제 쉴만큼 쉬어보니 다시 백엔드 개발에 더 깊이 관여할 마음가짐을 가지게 되었다. 또 마침 유튜브에 커서 기반 페이지네이션에 대해서 많이 뜨길래 관심을 갖게 되었고, 특히 대용량 데이터를 효율적으로 처리하기 위한이라는 워딩이 내 눈길을 끌린 김에 알아보게 되었다.
기존에 우리가 사용하던 오프셋 페이지네이션(페이지 번호와 크기 기반)은 다음과 같은 문제점이 있었다.
커서 페이지네이션은 '마지막으로 본 항목'을 기준점(커서)으로 삼아 다음 결과를 가져오는 방식이다.
예를 들어 SQL로 표현하면 아래와 같다.
SQLSELECT * FROM movie LIMIT 10 OFFSET 20; -- 3번째 페이지 (페이지당 10개)
SQLSELECT * FROM movie WHERE id > 1234 ORDER BY id ASC LIMIT 10; -- id 1234 이후의 레코드 10개
내 프로젝트에서는 NestJS와 TypeORM을 사용하고 있어, 이에 맞는 커서 페이지네이션을 구현했다. 핵심 구성 요소는 다음과 같다.
TypeScriptimport { IsArray, IsInt, IsOptional, IsString } from 'class-validator'; export class CursorPaginationDto { @IsString() @IsOptional() cursor?: string; // Base64로 인코딩된 커서 문자열 @IsArray() @IsString({ each: true, }) @IsOptional() // id_ASC, createdAt_DESC 형태로 정렬 기준과 방향 지정 order: string[] = ['id_DESC']; // 기본값은 ID 기준 내림차순 @IsInt() @IsOptional() take: number = 5; // 한 번에 가져올 항목 수 }
TypeScript// 커서 생성 함수 generateNextCursor<T>(result: T[], order: string[]): string | null { if (result.length === 0) return null; const lastItem = result[result.length - 1]; // 결과의 마지막 항목 const values = {}; // 정렬 기준이 되는 필드의 값을 추출 order.forEach((columnOrder) => { const [column] = columnOrder.split('_'); values[column] = lastItem[column]; }); // 커서 객체 생성 (값 + 정렬 정보) const cursorObj = { values, order }; // JSON 객체를 문자열로 변환 후 Base64 인코딩 const nextCursor = Buffer.from(JSON.stringify(cursorObj)).toString('base64'); return nextCursor; }
PLAIN// 인코딩 전 JSON 객체 { "values": { "id": 27, "createdAt": "2024-03-12T04:15:30.123Z" }, "order": ["id_DESC", "createdAt_DESC"] } // Base64 인코딩 후 eyJ2YWx1ZXMiOnsiaWQiOjI3LCJjcmVhdGVkQXQiOiIyMDI0LTAzLTEyVDA0OjE1OjMwLjEyM1oifSwib3JkZXIiOlsiaWRfREVTQyIsImNyZWF0ZWRBdF9ERVNDIL19
TypeScriptasync applyCursorPaginationParamsToQb<T>(qb: SelectQueryBuilder<T>, dto: CursorPaginationDto) { let { cursor, order, take } = dto; if (cursor) { // Base64 디코딩 및 JSON 파싱 const decodedCursor = Buffer.from(cursor, 'base64').toString('utf-8'); const cursorObj = JSON.parse(decodedCursor); order = cursorObj.order; // 커서에 저장된 정렬 순서 사용 const { values } = cursorObj; // WHERE 조건 구성을 위한 준비 const columns = Object.keys(values); // 내림차순(DESC)이면 < 연산자, 오름차순(ASC)이면 > 연산자 사용 const comparisonOperator = order.some((o) => o.endsWith('DESC')) ? '<' : '>'; // 테이블별칭.컬럼1, 테이블별칭.컬럼2 형태로 구성 const whereConditions = columns.map((c) => `${qb.alias}.${c}`).join(','); // :컬럼1, :컬럼2 형태의 파라미터 구성 const whereParams = columns.map((c) => `:${c}`).join(','); // 여러 컬럼을 동시에 비교하는 WHERE 조건 적용 // 예: (movie.id, movie.createdAt) < (:id, :createdAt) qb.where(`(${whereConditions}) ${comparisonOperator} (${whereParams})`, values); } // 정렬 조건 적용 for (let i = 0; i < order.length; i++) { const [column, direction] = order[i].split('_'); if (direction !== 'ASC' && direction !== 'DESC') { throw new BadRequestException('Order는 ASC 또는 DESC으로 입력해주세요!'); } // 첫 번째 컬럼은 orderBy, 나머지는 addOrderBy 사용 if (i === 0) { qb.orderBy(`${qb.alias}.${column}`, direction); } else { qb.addOrderBy(`${qb.alias}.${column}`, direction); } } // 가져올 레코드 수 제한 qb.take(take); // 결과 가져오기 const results = await qb.getMany(); // 다음 페이지 커서 생성 const nextCursor = this.generateNextCursor(results, order); return { qb, nextCursor }; }
TypeScript@Get() async getMovies(@Query() dto: CursorPaginationDto) { const qb = this.movieRepository .createQueryBuilder('movie') .leftJoinAndSelect('movie.director', 'director') .leftJoinAndSelect('movie.genres', 'genres'); // 커서 페이지네이션 적용 const { nextCursor } = await this.commonService.applyCursorPaginationParamsToQb(qb, dto); // 데이터와 카운트 가져오기 const [data, count] = await qb.getManyAndCount(); // 결과, 다음 페이지 커서, 총 개수 반환 return { data, nextCursor, count }; }
커서 페이지네이션의 핵심 장점 중 하나는 복합 정렬 조건을 효과적으로, 그리고 일관되게 처리할 수 있다는 것이다.
예를 들어 id_DESC,createdAt_DESC 형태로 정렬 조건을 줄 경우
이런 복합 조건에서도 커서는 정확한 위치를 가리키므로, 매우 큰 데이터셋에서도 일관된 결과를 반환할 수 있다.
구현에서 눈여겨볼 부분은 (movie.id, movie.createdAt) < (:id, :createdAt) 같은 SQL의 Row Value Constructor 문법이다. 이 구문은 여러 컬럼을 한 번에 비교할 수 있게 해준다.
< 연산자로 커서보다 작은(이전) 레코드 조회> 연산자로 커서보다 큰(이후) 레코드 조회인터넷에 떠도는 글을 인용하여 어떤 사람이 실제 프로덕션 환경에서 테스트한 결과, 오프셋 페이지네이션과 커서 페이지네이션의 성능 차이는 확연했다. PostgreSQL의 쿼리 실행 계획을 비교해보자
오프셋 페이지네이션 실행 계획
PLAINLimit (cost=25889.61..25890.36 rows=30 width=77) -> Sort (cost=25889.61..26015.61 rows=50400 width=77) Sort Key: created_at DESC -> Seq Scan on posts (cost=0.00..13697.00 rows=50400 width=77)
커서 페이지네이션 실행 계획
PLAINLimit (cost=0.43..36.10 rows=30 width=77) -> Index Scan Backward using posts_created_at_idx on posts (cost=0.43..67421.46 rows=56671 width=77) Filter: (created_at < '2024-01-01 12:00:00'::timestamp)
오프셋 페이지네이션은 모든 레코드를 정렬한 후 필요한 부분만 가져오는 반면, 커서 페이지네이션은 인덱스를 활용해 필요한 레코드만 효율적으로 가져온다. 이 차이는 데이터가 수백만 개 이상일 때 더욱 극명하게 드러난다.
O(n) 시간 복잡도의 비효율성
오프셋 페이지네이션은 데이터베이스가 OFFSET 값만큼의 레코드를 모두 읽고 버려야 하는 치명적인 문제가 있다.
SQL-- 1000번째 페이지(10,000번째 레코드부터)를 요청할 경우 SELECT * FROM posts ORDER BY created_at DESC LIMIT 10 OFFSET 9990;
이 쿼리의 실행 과정
즉, 페이지 번호가 커질수록 성능이 기하급수적으로 저하된다.
오프셋 페이지네이션의 또 다른 심각한 문제는 페이지 간 데이터 중복 또는 누락이다.
예를 들어
이 실행 계획은 데이터베이스가
비효율적인 작업을 수행함을 보여준다.
O(1) 시간 복잡도의 효율성
커서 페이지네이션은 마지막으로 본 레코드 이후의 데이터만 조회하는 방식으로, 시간 복잡도가 O(1)이다.
SQL-- 마지막으로 본 레코드(ID=500) 이후 10개만 조회 SELECT * FROM posts WHERE id < 500 ORDER BY id DESC LIMIT 10;
이 쿼리의 실행 과정
페이지 위치와 관계없이 항상 일정한 성능을 보장한다.
| 작업 | 오프셋 페이지네이션 | 커서 페이지네이션 |
|---|---|---|
| 데이터 접근 | O(n) - n은 OFFSET+LIMIT | O(k) - k는 LIMIT |
| 정렬 | O(n log n) - 전체 데이터 | O(1) - 인덱스 활용 |
| 메모리 사용 | 높음 (정렬 버퍼) | 낮음 (인덱스만 사용) |
| 디스크 I/O | 매우 높음 | 매우 낮음 |
오프셋 페이지네이션
SQLSELECT * FROM large_table ORDER BY id LIMIT 10 OFFSET 999990; -- 실행 시간: 10.2초
커서 페이지네이션
SQLSELECT * FROM large_table WHERE id < 1000 ORDER BY id DESC LIMIT 10; -- 실행 시간: 0.003초
약 3,400배의 성능 차이가 난다.
즉, 오프셋 페이지네이션의 인덱스를 효율적으로 활용할 수 없고, 커서 페이지네이션의 가장 큰 장점은 인덱스를 완벽하게 활용할 수 있다.
무한 스크롤이나 "더 불러오기" 버튼 기능을 구현할 때 커서 페이지네이션을 활용하면 효과적이다.
TypeScript// React 무한 스크롤 구현 예시 async function fetchNextPage(cursor) { const response = await fetch(`/api/movies?cursor=${cursor}&take=10`); const { data, nextCursor } = await response.json(); // 기존 데이터에 추가 setMovies(prev => [...prev, ...data]); // 다음 커서 저장 setNextCursor(nextCursor); // 더 불러올 데이터가 있는지 체크 setHasMore(nextCursor !== null); }
NestJS 생태계에서 가장 매력적인 것 중 하나는 인터셉터 패턴이다. 특히 RxJS와 결합하면 데이터베이스 트랜잭션 처리 같은 복잡한 작업도 우아하게 구현할 수 있다.
따라서 컨트롤러 메서드 실행 전후에 트랜잭션을 자동으로 시작하고 커밋/롤백하는 인터셉터를 만들었다.
TypeScriptimport { CallHandler, ExecutionContext, Injectable, NestInterceptor } from '@nestjs/common'; import { catchError, Observable, tap } from 'rxjs'; import { DataSource } from 'typeorm'; @Injectable() export class TransactionInterceptor implements NestInterceptor { constructor(private readonly dataSource: DataSource) {} async intercept(context: ExecutionContext, next: CallHandler<any>): Promise<Observable<any>> { const req = context.switchToHttp().getRequest(); const qr = this.dataSource.createQueryRunner(); await qr.connect(); await qr.startTransaction(); req.queryRunner = qr; return next.handle().pipe( catchError(async (e) => { await qr.rollbackTransaction(); await qr.release(); throw e; }), tap(async () => { await qr.commitTransaction(); await qr.release(); }), ); } }
이 인터셉터는 RxJS의 파이프 연산자를 활용하여
queryRunner를 주입catchError에서 트랜잭션을 롤백하고 예외를 다시 던짐tap에서 트랜잭션을 커밋하고 리소스를 해제실제 컨트롤러에서는 이렇게 간단하게 사용할 수 있다.
TypeScript@Post() @RBAC(Role.admin) @UseInterceptors(TransactionInterceptor) postMovie(@Body() body: CreateMovieDto, @Request() req) { return this.movieService.create(body, req.queryRunner); }
서비스 계층에서는 주입된 QueryRunner를 활용해 트랜잭션 내에서 일관된 데이터 조작을 할 수 있다. 이렇게 하면 여러 repository에 걸친 복잡한 CRUD 작업도 하나의 원자적 트랜잭션으로 처리할 수 있다.
이 접근 방식의 가장 큰 장점은 관심사 분리다. 비즈니스 로직에는 트랜잭션 관리 코드가 전혀 필요 없고, 필요한 경우에만 인터셉터를 적용하면 된다.
또 하나 유용한 패턴은 반복적인 요청을 최적화하기 위한 캐시 인터셉터이다.
TypeScriptimport { CallHandler, ExecutionContext, Injectable, NestInterceptor } from '@nestjs/common'; import { Observable, of, tap } from 'rxjs'; @Injectable() export class CacheInterceptor implements NestInterceptor { private cache = new Map<string, any>(); intercept(context: ExecutionContext, next: CallHandler<any>): Observable<any> | Promise<Observable<any>> { const request = context.switchToHttp().getRequest(); // /GET /movie const key = `${request.method}-${request.path}`; if (this.cache.has(key)) { return of(this.cache.get(key)); } return next.handle().pipe(tap((response) => this.cache.set(key, response))); } }
이 간단한 인메모리 캐시 인터셉터는 동일한 요청이 반복될 때 데이터베이스 쿼리 없이 바로 응답할 수 있게 해준다.
실제 프로덕션에서는 Redis 같은 외부 캐시 서비스와 TTL(Time-To-Live) 기능을 추가하는 것이 좋다.
마지막으로, API 성능을 모니터링하기 위한 응답 시간 측정 인터셉터도 구현했다.
TypeScriptimport { CallHandler, ExecutionContext, Injectable, NestInterceptor, } from '@nestjs/common'; import { Observable, tap } from 'rxjs'; @Injectable() export class ResponseTimeInterceptor implements NestInterceptor { intercept(context: ExecutionContext, next: CallHandler<any>): Observable<any> | Promise<Observable<any>> { const req = context.switchToHttp().getRequest(); const reqTime = Date.now(); return next.handle().pipe( tap(() => { const respTime = Date.now(); const diff = respTime - reqTime; console.log(`[${req.method} ${req.path}] ${diff}ms`); }), ); } }
이런 인터셉터는 각 API 요청의 처리 시간을 측정하고 로깅하여 성능 병목 지점을 찾는 데 도움을 준다. 실제 환경에서는 이 정보를 중앙 모니터링 시스템에 전송하여 전체 시스템의 성능을 분석하는 데 활용할 수 있다.
여담으로, 최근에 Claude 3.7이 출시되었다는 소식을 유튜브를 통해 듣고 창희님께 바로 말해서 사용해 보았다. 확실히 chain-of-thought 기능이 강화되어 파라미터를 더 효과적으로 처리하고 결과를 추론하는 능력이 향상되었다. 회사에서는 이 모델을 활용하여 백오피스 NestJS에서 데이터를 추출해 특정 스프레드시트에 업데이트하는 API를 개발했는데, 기존 API 코드 조각과 시트 필드명만 제공했더니 순식간에 코드를 생성해 냈다. 기존 GPT-4를 사용했다면 30분 이상, 수기로는 한 1시간 그 이상 걸렸을 작업이었는데, Claude 3.7은 한 5분 걸렸다…(인간의 시대의 끝이 도래했다.)
앞으로의 개발자는 더욱 AI를 효율적으로 활용하는 방법을 배워야 할 필요가 있다고 생각이 들었다…
여전히 우리 시스템에 개선할 점은 많다. 현재는 Route53의 가중 라우팅으로 진행 중이지만, 더 정교한 부하 분산과 장애 감지를 위한 전용 로드 밸런서 도입이 필요하다. 또한 완전한 Failover 구현과 세션이나 일부 데이터가 서버별로 독립적인 상태인 문제를 해결하기 위한 데이터 동기화 방안을 고민 중이다. 여건이 된다면 장기적으로는 Docker와 Kubernetes를 도입해 더 유연한 스케일링이 가능하도록 설계할 계획이다.
그나마 단일 장애점(Single Point of Failure)을 제거하고, 서비스 안정성을 크게 향상시킨 것이 이번 개모임 전에 얻은 큰 성과라고 생각한다.
따라서 좋지는 않다는 것은 알면서도 얻은 교훈은 "완벽한 솔루션보다 작동하는 솔루션이 낫다"는 것이다. 처음에는 더 정교한 방식을 고민했지만, 실용적인 접근으로 빠르게 문제를 해결할 수 있었다.
이 말이 와닿는 이유는 이제 그나마 밤새 서버 장애 알림에 시달리지 않고(사실 단 한번도 시달린 적은 없지만) 편안하게 잘 수 있게 된 것이다. 인프라 작업은 보이지 않는 곳에서 이루어지고, 사용자들은 모든 것이 정상적으로 작동할 때는 그 가치를 느끼지 못한다. 하지만 개발자로서 시스템의 안정성과 확장성을 고민하고 개선하는 과정은 꽤 보람찼다.
이제 프론트엔드 인력이 충원됨에 따라 원래 내가 처음 진행했던 NestJS에 다시 깊이 빠져들 시간이 된 것 같다. 창희님이 내가 처음에 만들었던 프로젝트를 크게 도와주셨는데, 이제는 내가 백엔드 개발에 더 깊이 빠져들면서 서비스의 안정성뿐만 아니라 확장성과 유지보수성도 개선하는 데 기여하고 싶다.
따라서 다음 개모임에는 또 다양한 이야기들이 생기지 않을까 기대한다.