이 문서의 목적. 2026-05-21 ~ 22 AWS Summit Seoul 의 AI Agent 관련 세션과 부스 인사이트를 종합하여, (1) AI Agent 를 잘 만들기 위한 운영 원칙과 (2) 그것을 우리 AI Agent 의 다음 고도화 단계에 어떻게 반영할 것인가를 단일 문서에서 끝낼 수 있도록 정리한 자료다.
원래는 사내 AI Agent 고도화 방향을 모색하기 위해 정리한 내부 발표 자료입니다. 하지만 현업에서 비슷한 기술적 고민을 마주하고 계실 분들께도 좋은 영감이 되길 바라며, Summit에서 얻은 인사이트를 블로그에 공개합니다.
다섯 세션 + 부스 라운드를 종합하면 결론은 단순하다.
AI Agent 를 잘 만든다는 것은 LLM 을 잘 호출하는 것이 아니라 — LLM 의 비결정성을 받아낼 외부 레이어 (관측 · 평가 · 가드 · 추상화 · 데이터 준비도)를 잘 만드는 것이다.
컨퍼런스에 가기 전, 코엑스 시연까지 우리가 구축해 둔 방향이 있었다 — 벡터 RAG (ChromaDB) · 단일 Specialist · LangGraph 등등. 다섯 세션을 듣고 돌아온 후의 가장 큰 수확은 두 가지였다.
이 두 가지가 합쳐져 적어도 같은 방향이 맞다는 확신을 얻었다. 자체 분석으로 미리 마련해 둔 청사진을 컨퍼런스가 검증해 준 것이 아니라 — 이미 가던 방향의 타당성이 확인되고, 멈춰 있던 다음 단계를 컨퍼런스가 알려준 쪽에 가깝다.
본 문서는 그 두 가지 참조된 골격과 참고할 다음 단계의 매핑을 한 흐름으로 정리해 둔 것이다. 적용 항목의 우선순위도 함께 짚어두지만, 결정의 무게는 어디까지나 팀 내부 논의에 둔다.
본격적인 AI Agent 용어 사전으로 들어가기 전에, 컨퍼런스 전반에 깔려있던 두 가지 시대 메시지를 먼저 짚어둔다. 한 줄로 — 도구의 변화 (AI-DLC) 와 사람의 변화 (르네상스형 개발자) 가 동시에 일어나고 있다.
이 두 메시지는 다섯 세션의 어느 한 곳에서만 나온 게 아니라, 컨퍼런스 전반에 공기처럼 깔려있던 시대 배경. 다음 장 (용어 사전) 의 모든 항목이 왜 필요한가의 배경을 여기서 먼저 짚어두면, 이후의 모든 논의가 조각이 아니라 큰 그림으로 읽힌다.
공장 자동화의 첫 단계는 기계 한 대 도입이었지만, 진짜 생산성 폭발은 공정 전체를 자동화에 맞게 재설계한 뒤에야 일어났다. AI 코딩도 같은 흐름으로 보인다.
이번 컨퍼런스에서 가장 명료하게 짚어준 메시지가 AI-DLC (AI Driven Development Lifecycle)였다.
AI 코딩 도구만 도입해서는 생산성 향상이 10~15% 에 그치고, METR 연구에 따르면 숙련 개발자는 오히려 19% 더 느려진다.
원인은 단순하다.
코딩이 빨라져도 개발자의 실제 업무에서 코딩이 차지하는 비중은 약 20 % 정도다.
설계·분석·소통·의사결정·테스트·검증이 나머지 80 % 를 차지하는데, 그 80 % 에는 AI 가 들어가 있지 않다.
코딩 한 줄을 빠르게 작성하는 국소 최적화가 전체 라이프사이클을 자동으로 빠르게 만들어주지는 않는다는 점이 핵심이다.
AI-DLC 의 사상은 다음과 같다.
한 줄짜리 코드 생성이 아니라 라이프사이클 전체를 AI 네이티브로 재설계한다는 발상이다.
단계무엇을 하나누가 결정하나Inception (인셉션)AI 가 요구사항을 이해하고 전체 설계를 제안. 사용자 스토리·작업 단위 (Unit) 분해까지 수행AI 가 초안, 사람이 검증·승인Construction (컨스트럭션)AI 가 인셉션 결정에 기반해 코드와 인프라를 생성·테스트AI 가 대부분, 사람이 분기점 의사결정Operation (오퍼레이션)빌드·테스트·배포 실행. 향후 자동화 워크플로 확장 예정DevOps 자동화 + 사람 모니터링
세 단계 모두 Human-in-the-loop가 체계적으로 자리 잡고 있다는 점이 핵심이다.
AI Managed (사람이 들어가지 않음) 도 AI Assisted (사람 중심에 AI 일부) 도 아닌 AI Driven 으로 — AI 가 대부분의 작업을 수행하되 중요한 분기에서 사람이 검증·승인하는 방식이다.
발표 현장에서 공유된 사례에 따르면, 일정 규모의 조직이 AI-DLC 를 실제로 도입한 결과 스프린트가 절반 수준으로 단축되고 요구사항 도출부터 코드 생성까지의 전 사이클이 1.5~2 배 빠르게 진행된 것으로 보고되었다.
코딩만 빨라진 것이 아니라 라이프사이클 전체가 빨라진 셈이다.
르네상스 시대의 다빈치는 화가이자 발명가이자 해부학자이자 건축가였다.
AI 가 각 분야의 전문 보조를 해주면, 한 사람이 그 모든 영역을 원래 자기 영역처럼 다루기에 가까워진다. 이게 컨퍼런스 전반에 공통으로 깔려있던 두 번째 시대 메시지였다.
개발자의 정체성이 바뀌고 있다.
과거의 모델은 1 인 1 기능으로, 백엔드는 백엔드만 / 프론트는 프론트만 / 데이터는 데이터만 처리를 했다.
영역 사이는 handoff (다른 사람에게 넘김)로 이어지고, handoff 마다 컨텍스트가 깎인다.
새 모델은 1 인 1 문제 해결, 한 사람이 문제 발견부터 배포까지 풀스택으로 처리한다. AI 와 표준화된 환경이 갖춰져 있어, 원래 자신의 영역이 아니던 코드도 해당 영역 전문가의 직접 개입 없이 다룰 수 있다.
핵심 효과는 단순하다,
handoff 가 줄어들수록 전체 사이클이 짧아진다.
한 사람의 머릿속에서 문제 정의·설계·구현·검증·배포가 끊김 없이 이어지므로, 컨텍스트 손실로 인한 재작업이 줄어든다.
다만 한 사람이 모든 것을 잘하는 천재 개발자가 되라는 의미는 아니다. 르네상스형은 천재의 능력이 아니라 환경 (도구 + 표준 + AI 협업) 의 산물로 봐야 한다.
이 환경이 갖춰져 있지 않으면 1인 다영역 시도는 품질이 낮은 코드의 양산으로 끝난다. 따라서 다음 네 가지 환경 요소가 전제되어야 한다.
환경 요소설명Context Repo (조직 메모리)도메인 지식·결정·표준을 AI 가 읽을 수 있는 형태로 정리한 사내 저장소. 어느 개발자가 다른 영역을 다루더라도 해당 영역의 맥락을 AI 가 자동으로 주입한다.표준 MCP 도구디자인 시스템·코딩 표준·아키텍처 원칙을 MCP 도구로 노출. 어느 영역을 다루더라도 동일한 표준으로 결과물이 산출된다.Expert 그룹모든 구성원이 르네상스형이 될 수는 없다. 각 영역의 깊은 전문가가 일급 자문 역할을 유지한다. 1 인 다영역 개발자가 주요 분기점에서 자문을 구하는 대상이다.Skill·Plugin 라이브러리Claude Code 의 Skill / Tool / Plugin 을 조직 차원에서 표준화·공유. 개인이 만든 효과적 패턴이 즉시 조직 자산으로 전환된다.
핵심 사상은 개발자 한 명이 모든 것을 잘하는 시대가 아니라, AI 와 표준화된 환경이 있어서 개발자 한 명이 더 많은 영역을 다룰 수 있는 시대로 옮겨가는 흐름이다.
도구가 사람의 능력을 확장한 것이지, 사람이 갑자기 다재다능해진 것은 아니다.
발표를 듣다 보면 Trajectory · Golden Dataset · Programmatic Evaluator 같은 낯선 용어가 빠르게 지나간다. 본격 논의 전에 자주 등장한 12 개 용어를 일상 비유부터 시작해 풀어둔다. 필요한 항목만 발췌해서 봐도 된다.
챗봇은 전화 상담원이고, AI Agent 는 직접 사무실을 돌아다니며 일을 처리해주는 인턴이다.
핵심 차이는 행동 권한. AI Agent 는 파일을 열고 / API 를 부르고 / 다른 프로그램을 실행하고 / 다른 AI 와 협업한다. 사람이 매번 옆에서 "다음 뭐 할까요?" 안 물어봐도 알아서 다음 단계를 결정한다.
우리 AI Agent는 반자율 위치. 사용자가 데이터를 올리면 에이전트가 분석 블록을 추천·조립·실행하고, 최종 채택 여부는 사람이 결정한다.
요리할 때 레시피 읽기 → 재료 자르기 → 맛보기 → 다시 레시피 읽기 → 간 조절 같은 사이클을 도는 것.
AI Agent 도 똑같다. 한 번에 답을 뱉는 게 아니라 — 생각하고 → 도구를 부르고 → 결과를 보고 → 다시 생각하는 작은 사이클을 여러 번 돈다. 이걸 영어로 ReAct (Reasoning + Acting, 추론 + 행동) 패턴이라 부른다.
Mermaid스크롤로 확대 · 드래그로 이동
공장 자동화 라인의 QA 검수원과 같다. 라인 끝에 사람이 서서 통과·반려 도장만 찍는다. 사람이 모든 부품을 만들지 않지만, 결정적 분기에서는 사람의 도장이 있어야 다음 단계로 넘어간다.
AI 와 사람이 어떤 관계로 일하는지 — 자동화 등급을 세 단계로 나눠본다.
등급사람의 위치적용 영역AI Assisted사람이 핸들 잡고, AI 가 옆에서 보조코드 어시스턴트 · 글쓰기 도우미 — 사람이 운전AI Driven (HITL)AI 가 대부분 자율 수행, 결정적 분기에서 사람이 확인·승인코드 배포 · 거래 승인 · 분석 채택 — 사고 시 비용 큰 영역AI Managed사람 안 들어감사고 위험 작은 자동화 — RPA · 단순 조회
Human-in-the-loop (HITL) 는 가운데 AI Driven 등급의 표준 사상. AI 효율 + 사람 책임의 경계를 한 라인에 묶어준다.
왜 핵심인가
LLM 은 비결정적이라 100 % 자동화는 위험. 같은 입력에도 답이 달라지므로, 사고 시 비용이 큰 분기에는 사람이 반드시 들어가야 한다. 이번 컨퍼런스 다섯 세션 모두 같은 사상 위에 있다. (Nova Act의 지능적 인간 개입 기본 내장 · AI-DLC 의 세 단계 사람 검증 · Strands Agents 의 승인 게이트 · 미래에셋의 컴플라이언스 검토 단계 · 빗썸의 운영자 통제 + 감사 로그.)
Tool은 드라이버 한 개, SKILL은 드라이버 + 부품 + 설명서가 들어있는 공구함 한 통.
Progressive Disclosure (점진적 공개) — 풀어쓰면.
"평소엔 목차만 보여주다가, 진짜 필요할 때만 본문을 펼쳐 보여준다".
AI가 한 번에 처리할 수 있는 글자 수는 제한이 있다 (이걸 컨텍스트 한도라고 부른다). 만약 SKILL 30 개를 설치해두고 매번 모든 SKILL의 본문을 다 읽힌다면, 본문만으로도 한도가 꽉 차서 정작 사용자 질문을 들을 자리가 없어진다.
해결책 — 3 단계로 나눠서 필요할 때만 펼쳐 보여준다:
단계무엇이 펼쳐지나비유Level 1 — 항상 들고 있음SKILL 이름과 한 줄 설명만 (이름표 수준)책장에 책 제목만 보이는 상태Level 2 — 트리거되면 펼침실제 지침 본문 (어떻게 쓰는지)그 책을 꺼내서 본문을 폄Level 3 — 실행할 때만 봄그 안의 코드·결과물책의 부록 코드를 실행 — 결과만 본다
이렇게 단계를 나누면 SKILL 수십 개 설치해도 평소엔 이름표만 들고 있다가, 사용자가 재무 분석을 부탁할 때만 재무 분석 SKILL의 본문을 펼쳐서 읽는다. 컨텍스트 한도를 압박하지 않으면서 많은 능력을 보유하는 패턴.
Trace = CCTV 녹화 풀버전, Trajectory = CCTV 에서 동선만 따로 추출한 지도.
[데이터 로드 → 결측치 처리 → 회귀 분석 → 시각화].왜 둘 다 필요한가 — 답이 맞아 보여도 과정이 틀렸으면 사고다. 결제 도구를 두 번 부른 에이전트의 응답이 "결제 완료" 라도, 실제론 중복 결제가 일어났다. Trajectory를 봐야 잡힌다.
학교의 오답 노트와 똑같다.
운영에서 에이전트가 한 번 잘못 답한 사례를 "입력 → 정답 출력"한 쌍으로 모아둔다. 다음 배포 직전에 이 정답지로 자동 테스트를 돌리고, 같은 실패가 또 나면 배포 자체를 막아버린다.
왜 일반 코드 테스트보다 중요한가 — AI Agent는 비결정적이다. 같은 입력이라도 매번 똑같이 답하지 않는다. 그래서 한 번 고친 버그가 다음 배포에서 또 살아날 확률이 일반 코드보다 훨씬 높다. 오답 노트가 없으면 같은 사고를 반복한다.
주관식 답안 채점은 사람 시험관 (LLM as Judge) 이 점수를 매기고, 객관식 OMR은 기계 (Programmatic Evaluator) 가 정답·오답만 빠르게 가린다.
왜 이 구분이 중요한가
명확한 답에 LLM 을 쓰면 비용이 폭주한다. SQL 유효성 검사 같은 결정적 검증을 GPT 한테 시키면 한 번에 몇 백 원씩 쓴다. 그냥 Python sql.parse() 한 줄로 끝낼 일을. LLM 을 안 쓰는 게 맞는 영역이 따로 존재한다. — 이 분리가 핵심.
시험 문제의 정답을 체크리스트 / 모범 답안 / 풀이 순서 세 방식으로 적어두는 것과 같다.
에이전트를 평가하려면 "정답이 뭔지" 를 어떻게든 적어둬야 한다. 그런데 정답이 글 한 줄 일 수도 있고 충족해야 할 조건들 일 수도 있고 반드시 따라야 하는 절차 일 수도 있다. 그래서 정답을 세 형태로 나눠 적는다.
형태무엇을 적는가비유언제 쓰나Assertion (단언)답이 반드시 만족해야 하는 조건들의 목록시험 문제의 체크리스트"응답에 욕설 없을 것", "법적 면책 문구 포함" 같은 규정 준수Expected Response (기대 응답)답안 본문 자체모범 답안"FAQ 답변", "수학 문제 정답 숫자"Expected Trajectory (기대 경로)에이전트가 반드시 거쳐야 하는 도구 호출 순서풀이 과정 순서다단계 워크플로 (감사 추적이 중요한 경우)
특히 Expected Trajectory가 중요한 이유
시스템 프롬프트에 "먼저 X 호출하고 그 다음 Y 호출해"라고 적어둬도 에이전트가 그 순서대로 한다는 보장이 없다. LLM 은 자기 마음대로 순서를 바꾸기도 한다. 그래서 실제 호출 순서가 기대 순서와 같았는지를 사후에 검증해야 한다.
발표 준비를 내 책상에서 혼자 연습 → 회의실에서 동료 앞 리허설 → 실제 청중 앞 발표 세 단계로 하는 것과 같다.
평가 무대를 세 곳으로 나눠서, 각 무대에서 발견된 실패가 다시 정답지로 흘러들어 가는 폐쇄 사이클을 만든다.
무대어디서무엇을Inner Loop (내부 루프)개발자 데스크탑코드 수정하고 즉시 빠르게 평가하는 반복 (분 단위)Outer Loop (외부 루프)CI/CD (배포 자동화 파이프라인)배포 직전의 자동 검문소 — 정답지 통과 못 하면 배포 차단Production Loop (운영 루프)진짜 운영 환경실제 사용자 트래픽 위에서 지속적으로 품질 감시 — 새로 발견된 실패를 정답지에 자동 추가
Mermaid스크롤로 확대 · 드래그로 이동
이 사이클의 핵심
실패가 자동으로 다음 회귀 방지 자산으로 전환 된다. 사람이 일일이 "이거 다시 안 나오게 해주세요" 등록하지 않아도, 운영 실패가 그대로 다음 배포의 검문 기준이 된다.
회사 정문의 보안 게이트와 같다. 외부에서 들어오는 모든 사람이 한 군데서 신분증 찍고 / 출입 기록 남기고 / 보안 검색 받게 하는 그 게이트.
LLM Gateway 도 똑같다. 코드 곳곳에서 제각각 OpenAI / Claude / Bedrock 을 부르는 게 아니라, 모든 LLM 호출을 한 통로로 모아서 통과시킨다. 그 통로에서:
게이트가 없으면 — 모델 바꿀 때마다 코드 11 군데를 동시에 수정해야 하고, 누가 얼마 썼는지 모르고, 보안 정책이 곳곳에서 달라진다. 그래서 단일 통로가 필요하다.
솔직히 짚어두면, 우리 개발팀 입장에서는 LLM Gateway 사상이 우리 개발 환경에 시급하게 적용될 일은 작다. 우리 팀이 일괄적으로 AI 도구를 사용하지는 않기 때문이다.
빗썸처럼 수백 명의 개발자가 동시에 Claude Code 를 부르고 비용·감사가 폭발하는 상황이 아니다.
그러나 우리 프로젝트 제품 안에 AI Agent 가 들어가서 고객사 사용자가 그것을 쓰게 되는 시점 부터는 이야기가 완전히 달라진다. 관리자 페이지에서 다음 네 가지를 제품 기능으로 만들어야한다.
관리자 페이지 기능무엇이 필요한가LLM Gateway 사상에서 빌려오는 부분모델 변경고객사가 어떤 LLM 을 쓸지 직접 선택 (Bedrock Claude / OpenAI / 사내 Ollama)라우팅 — 환경·정책에 따라 모델을 동적으로 분배사용 추적어떤 사용자 / 어떤 세션이 / 어떤 프롬프트를 보냈는지인증 + 감사 로그 — 호출자 식별 + 프롬프트·응답 영구 보관감사운영 사고 시 누가 언제 어떤 응답을 받았는지 재구성감사 로그 — Trajectory 와 결합해 한 사이클 풀 추적비용 거버넌스고객사별·팀별 토큰 사용량과 비용. 한도 초과 시 차단비용 추적 — 호출당 토큰·요금 누적, 임계값 게이트
즉 LLM Gateway 는 우리 개발 환경의 도구가 아니라 우리 프로젝트가 고객에게 제공할 관리자 페이지의 기반 사상. 빗썸이 직원이 쓰는 Claude Code의 거버넌스를 만든 패턴과 비슷하게 우리 프로젝트가 고객사 사용자가 쓰는 AI Agent의 거버넌스를 같은 패턴으로 만든다.
그래서 개발팀이 알아둬야 하는 개념으은 우리 일상 워크플로우에는 안 들어와도, 제품 기능 설계에는 그대로 들어올 확률이 높다는 것을 인지하고 있어야한다.
공항 보안 검색처럼 입국 심사 → 휴대품 X-ray → 게이트 출입 확인 세 단계가 서로 독립으로 작동한다. 한 곳에서 못 잡아도 다음에서 잡힌다. 핵심 사상은 에이전트는 진화하지만 보호막은 정적으로 유지 되어야 한다는 것이다.
보호막을 에이전트 코드와 같은 자리에 넣으면, 사고 시 어디부터 뚫린 건지 추적 불가능하다.
우리 프로젝트 적용성은 낮다. 우리는 사내 분석 도구라 외부 인젝션 위협이 작고, 다층 가드레일 명시화는 우선순위 낮은 항목이다.
3 단계 분류 (입력 / 정책 / 출력 가드) + 발표별 사례 + 빗썸 5 대 보안 기준과의 거리는 추가 아이디어 에 따로 분리해 두었다.
도서관의 두 사서 비유.
한 명은 제목·표지만 보고 비슷해 보이는 책을 가져다 준다. 다른 한 명은 모든 책의 저자·주제·시대·인용 관계를 머릿속에 그려놓고, "이 책과 같은 시대의 미스터리 소설 중 평론에서 자주 인용되는 것" 같은 복합 질문을 한 번에 풀어낸다.
후자가 온톨로지를 가진 사서이다.
온톨로지 (Ontology) 란.
단어 자체는 존재론이라는 철학 용어이지만, AI / 데이터 맥락에서는 단순하다.
어떤 도메인에 어떤 개체 (Entity) 가 있고, 그 개체들이 서로 어떤 관계 (Relation)로 연결되는지 명시적으로 정의한 지식 구조를 의미한다.
풀어쓰면 지식의 지도.
세 가지 구성 요소만 알면 된다.
요소무엇인가우리 프로젝트의 예Entity (개체)도메인의 핵심 명사 — 사람·물건·개념Block · Column · Dataset · DomainTerm (예: "매출", "고객 ID")Relation (관계)개체와 개체를 잇는 동사Block --[REQUIRES_BEFORE]--> Block · DomainTerm --[MAPS_TO]--> ColumnConstraint (제약)관계의 허용 / 금지 / 예외 규칙Block --[STRICTLY_PROHIBITED_WITH]--> Block (특정 블록 조합 금지)
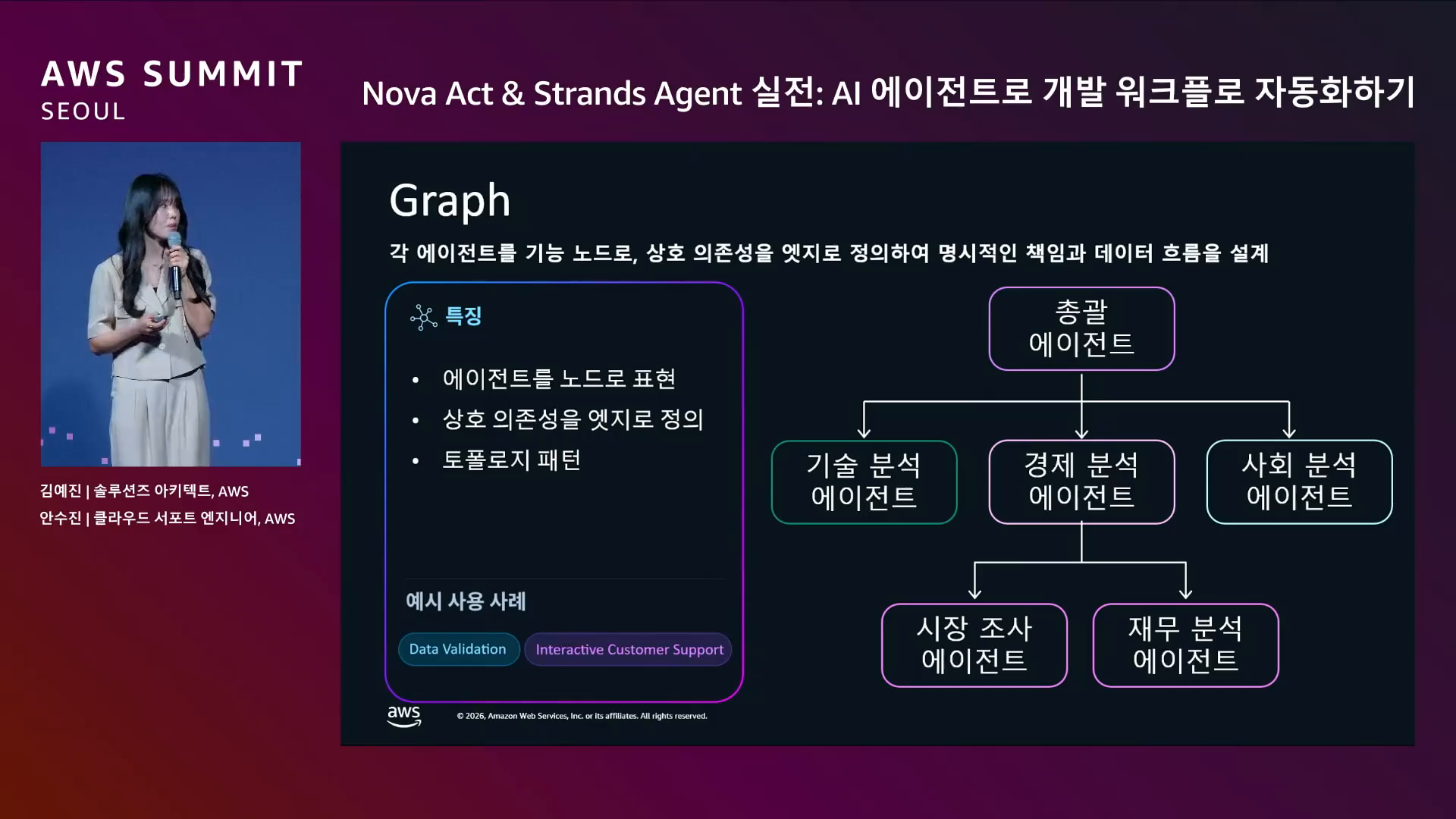
왜 지금 중요한가. 벡터 RAG 는 비슷한 문서를 찾아주지만 관계를 따라가지 못한다. "보험금 분석"이라는 사용자 발화가 들어왔을 때, 벡터 RAG 는 보험금 단어가 들어간 블록만 찾는다. 온톨로지가 있으면 "보험금 → ClaimAmount 컬럼 → 숫자형 → 이 컬럼에 적용 가능한 분석 블록"의 3 단계 관계 추적이 한 쿼리로 가능해진다.
미래에셋 GraphRAG 발표가 정확히 이 사상을 코드로 보여줬다.
보험 약관의 "보장 → 면책 → 면책의 예외" 같은 세 번 꺾이는 문장을 벡터 한 채널로는 절대 못 잡고, 그래프 엣지로 박아야 컴플라이언스 사고를 막을 수 있다.
한 줄 정리 — 벡터 검색이 유사도만 보는 한 명의 직원이라면, 온톨로지 + 그래프 검색은 관계의 지도를 머릿속에 가진 베테랑 사서다. 다음 절의 Hybrid Search 가 벡터 + 그래프 채널을 동시에 굴리는 이유가 여기 있다.
책을 찾을 때 제목만 보고 찾기 / 줄거리로 찾기 / 같은 작가 책으로 찾기 / 분류 코드로 찾기 — 네 방식을 다 써야 진짜 원하는 책이 나오는 것과 같다.
사용자가 말하는 자연어 한 문장은 한 가지 검색으로 다 못 잡는다. 예를 들어:
사용자 발화어떤 검색이 잘 잡나"히트맵 그려줘"벡터 검색 — "heatmap" 이라는 단어가 카탈로그에 없어도 의미가 비슷한 항목을 찾아준다"TVS0008 옵션"키워드 검색 (BM25) — 정확한 코드는 의미 검색보다 철자 일치 검색이 정확"보험금 분석"그래프 검색 — "보험금 → ClaimAmount 컬럼 → 숫자형 컬럼" 같은 관계를 따라가는 검색"category=visualization 인 블록"문서 필터 — 컬렉션에서 정확한 필드값만 추리는 검색
Hybrid Search = 위 네 가지를 동시에 굴리고 결과를 합산한다.
네 채널이 코드로 보면 이렇게 다르다 — 모두 최상위 5 개를 가져온다 까지가 한 줄.
Python# 1. 벡터 검색 — "히트맵 그려줘" query_vec = embed("히트맵 그려줘") hits_vec = qdrant.search(collection="block_catalog", query=query_vec, limit=5)
Python# 2. 키워드 검색 (BM25) — "TVS0008 옵션" from rank_bm25 import BM25Okapi bm25 = BM25Okapi(corpus_tokens) # 카탈로그 텍스트를 토큰화해둔 것 hits_bm25 = bm25.get_top_n(["TVS0008"], corpus_ids, n=5)
CYPHER// 3. 그래프 검색 — "보험금 분석" MATCH (t:DomainTerm {name:"보험금"})-[:MAPS_TO_COLUMN]->(c:Column)-[:USED_IN]->(b:Block) RETURN b.id LIMIT 5
Python# 4. 문서 필터 — "category=visualization 인 블록" hits_doc = mongo.block_catalog.find({"category": "visualization"}).limit(5)
그런데 네 검색 결과를 어떻게 한 줄로 합치냐가 문제이다. 그래서 표준 알고리즘 하나가 있다.
— RRF (Reciprocal Rank Fusion, "역순위 합산"). 각 검색에서 몇 등을 했는지만 가지고 점수를 매겨 합산한다.
채널마다 점수 척도가 달라도 순위만 보면 공정하게 합산 가능하다.
Python# RRF — 네 채널의 "순위" 만 모아서 공정 합산 (k 는 노이즈 완충 상수, 보통 60) def rrf(channels: list[list[str]], k: int = 60) -> list[tuple[str, float]]: scores: dict[str, float] = {} for ranks in channels: # 각 채널의 [doc_id, ...] 리스트 for r, doc_id in enumerate(ranks): scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + r + 1) return sorted(scores.items(), key=lambda x: -x[1]) # 사용 예 final = rrf([hits_vec, hits_bm25, hits_graph, hits_doc])[:5]
마이크로소프트의 GraphRAG 논문이 보고하기로는 벡터 검색만 쓸 때보다 정확도 +15~30%, 재현율 +20~40% 향상. 우리에게 의미 있는 이유 — 벡터 한 채널만으로 결정하던 "조기 리턴 사고" (의미 유사도 한 번 봐서 너무 빨리 답해버리는 사고) 가 네 채널 합의로 구조적으로 줄어든다.
책장이 어지러우면 똑똑한 사서도 책을 못 찾는다.
AI Agent 가 좋은 결과를 내려면 모델이 똑똑해야 하는 게 아니라, 데이터가 AI 가 읽기 좋은 상태로 정리되어 있어야 한다. 컬럼명이 일관되어 있고, 의미 분류가 되어 있고, 도메인 표준에 맞춰져 있고, 변경 이력이 남아있는 상태.
MIT 통계 — GenAI 프로젝트의 95% 가 파일럿에서 프로덕션으로 못 간다. 이 95% 가 실패하는 진짜 원인은 LLM 성능이 부족해서가 아니라 — 데이터가 AI 가 이해할 수 있는 상태로 준비되어 있지 않아서. 미래에셋 발표가 강조한 핵심 메시지가 정확히 이거였다.
다섯 세션 모두 도메인은 달랐지만 AI Agent 를 잘 만든다는 것의 본질을 다섯 각도에서 보여줬다. 각 세션마다 발표장에서 들은 한 줄과 가장 인상 깊었던 장면, 그리고 우리에게 무엇을 가르쳐주는가를 풀어둔다.
"단 몇 줄의 코드로 Strands 에이전트를 만들고, Self-extending / Self-updating / Self-improving 기능으로 점진적으로 능력을 키워나가다, 프로덕션에 올릴 때만 AgentCore 같은 서비스로 보안·스케일·비용을 고려하시면 됩니다." — AWS 박경수 SA
발표의 핵심 메시지는 처음부터 거창하게 짜지 말고 단순하게 시작해서 스스로 진화시키라는 거였다. 발표자가 강조한 자가 진화 패턴은 세 가지:
가장 인상적이었던 장면은 두 번째 패턴의 라이브 데모. 발표자가 에이전트에게 "내 이름은 경수야"라고 말하자, 에이전트가 잠깐 멈추더니 자기 시스템 프롬프트 파일을 열어서 그 사실을 직접 기록했다. 다음 대화 세션에서도 그 사실이 살아있었다. "스스로 진화한다"라는 추상적인 표현이 30 초짜리 데모로 코드 레벨로 구체화된 순간이었다.
이런 자가 진화 패턴에 공통으로 들어있는 골격은 Retrieve → Modify → Persist라는 3 단계 루프. 지금 어떤 상태인지 읽고 → 필요한 변경을 만들고 → 영속 저장소에 기록한다. 이 골격이 도구·프롬프트·지식 베이스 어떤 대상이든 똑같이 작동한다.
또 하나 짚어둘 만한 개념이 Model-driven 접근. 개발자가 그래프를 직접 짜지 않고 도구 목록과 목표만 주면 모델이 알아서 어떤 순서로 어떤 도구를 부를지 결정한다. 이게 가능한 이유는 LLM 의 추론 능력이 일정 수준 이상 올라왔기 때문이다.
다만 결정론 보장이 필요한 도메인 (분석 워크플로우 같은) 에서는 여전히 Graph-driven (LangGraph) 이 정공법이라는 점도 발표자가 분명히 했다. — 우열이 아니라 트레이드오프다.
우리에게 의미하는 바는 우리가 LangGraph 기반 Graph-driven을 채택한 건 결정론 우선의 의도적 선택이라는 게 외부 시각에서도 적절하다는 확인했고, 그리고 자가 진화 패턴의 일부 (특히 자가 학습) 는 우리 시스템에도 도입 가치가 있다는 점이다.
Strands는 몇 줄짜리 코드로 에이전트가 만들어지고 자가 진화까지 빌트인 및 개발 속도 측면에서 압도적이다.
그럼에도 우리 프로젝트는 Strands 를 프레임워크로 채택하지 않는다.
이유는 단순하다. — AWS 귀속적이기 때문이다.
Strands 는 Bedrock / AgentCore / Knowledge Bases 같은 AWS 서비스와 깊게 묶여 동작하도록 설계되어 있다. 그대로 쓰면 AWS 생태계에 발이 묶인다.
우리 프로젝트는 SaaS 한 가지로 배포하지 않는다. 고객사의 운영 형태가 두 갈래로 갈린다.
배포 형태환경AWS 의존 가능 여부SaaS 배포우리 클라우드가능 (그러나 유일한 형태가 아님)내부 로컬 설치 (On-Premise)고객사 내부망 · 망분리 환경 · 폐쇄망AWS 호출 자체가 사실상불가능
특히 공공 / 제조 보안 사이트처럼 망분리 + 외부 인터넷 차단 환경에서는 Bedrock 호출이 원천적으로 안 된다.
그러면 Strands 의 자가 진화 빌트인이 그 환경에서 그대로 깨진다.
그래서 현재 결론은 — 사상은 차용 / 프레임워크 자체는 비채택.
llm_factory facade 뒤에 Bedrock / OpenAI / Ollama를 동등하게 두어, 환경에 따라 갈아끼움.user_preferences 컬렉션 조합으로 비슷한 효과를 낸다.핵심 사상
어디서 돌아갈지 모르는 시스템은 돌아갈 수 있는 모든 환경에서 같은 사상으로 작동해야 한다.
AWS 가 없는 곳에서도 우리 프로젝트는 같은 결정론 / 같은 진화 패턴 / 같은 거버넌스로 돌아가야 한다. 그래서 Strands 의 사상은 들고 오되 구현체는 우리 스택에 맞춰 다시 짠다.
같은 에이전트 프레임워크라는 이름을 쓰지만 사상이 다르다.
항목LangGraph (우리 프로젝트가 쓰는 것)Strands경로 결정개발자가 그래프를 명시적으로 정의 (Plan → Validate → Respond → Reflect 노드를 코드로)모델이 런타임에 결정 — 도구 목록과 목표만 주고 호출 순서는 LLM 이 추론결정론강함 — 같은 입력에 같은 경로약함 — 같은 입력에 다른 경로 가능 (확률적)자가 진화별도 구현 필요빌트인 (Self-extending / Self-updating / Self-improving)디버깅그래프 시각화로 흐름 따라가기 쉬움런타임 추론 trace 를 봐야 함적합 도메인분석 워크플로우 · 결정론 우선 · 감사 추적 필요탐색 · 연구 · 진화 우선 · 자유 형식 응답개발자 통제력높음 — 어디서 무엇이 일어날지 코드로 박힘낮음 — 모델이 알아서
선택의 기준. 결정론 보장이 필요한가가 갈림길. 분석 결과를 사용자가 재현할 수 있어야 한다면 LangGraph가 정공법. 사용자가 대화하며 점진적으로 발견하는 도메인이라면 Strands가 적합.
발표에서 가장 인상적이었던 장면. 박경수 SA가 직접 시연했다.
— 사용자가 "내 이름은 경수야"라고 말하자 에이전트가 자기 시스템 프롬프트 파일을 직접 수정. 다음 세션에서도 그 사실이 살아있다.
Video
MP4
라이브 데모 발췌 (Strands 세션 23:20~24:30, 박경수 SA). 왼쪽 화면이 방금 만든 에이전트 코드 실행 부분, 오른쪽이 에이전트가 직접 수정하고 있는 시스템 프롬프트 파일. 사용자 발화 → 에이전트 자가 도구 호출 → 파일 한 줄 추가 → 다음 호출 시 즉시 반영의 한 사이클이 사람 개입 없이 자동으로 일어나는 게 핵심.
영상에서 한 번에 잡기 어려운 메커니즘만 글로 짚어둔다.
LangGraph에는 같은 빌트인 기능이 없다. 같은 효과를 내려면 별도 메모리 store + 매 노드 진입 시 store 조회 + store 쓰기 도구를 직접 구현해야 한다. 우리 프로젝트에서 사용자 선호 학습 정도의 단순 학습은 MongoDB user_preferences 컬렉션 + Specialist 진입 시 조회 패턴으로 비슷한 효과를 낼 수 있다.
하지만 완전한 자가 진화까지 가려면 Strands 사상 도입이 필요하다.
"에이전트는 소리 없이 실패합니다. 실패한 것도 감춰집니다. 왜냐하면 스스로 교정하기 때문에." — AWS AgentCore 팀 김무현 SA
발표자가 본인이 직접 만들고 있는 서비스를 소개하는 자리였는데, 이 한 줄이 발표 전체를 관통했다.
에이전트는 잘 작동하는 척하기가 일반 코드보다 쉽다. 한 단계에서 잘못 판단해도 다음 단계에서 자기가 알아서 보정해버리니까, 겉으로 보면 "최종 응답은 맞았네" 가 된다.
하지만 그 안에서 어떤 도구를 잘못 불렀거나, 데이터를 두 번 보냈거나, 결정적 단계를 건너뛰었거나 사고가 누적된다.
발표자가 정리한 에이전트 개발자가 만나는 4가지 도전도 명확했다.
이걸 푸는 도구로 발표가 보여준 게 AgentCore Evaluation이었다. 핵심은 평가를 한 줄 응답이 아니라 전체 궤적으로 본다는 것. 세 가지 평가 단위 (LEVEL) 가 정의되어 있다
세션 단위 (대화 전체), 트레이스 단위 (한 번의 실행), 툴 단위 (도구 호출 하나). 어느 단위에서 사고가 났는지 분리해서 측정 가능하다.
그리고 흥미로운 신규 기능 두 가지가 공개됐다.
발표의 정수는 마지막 3 Loop + Golden Dataset Flywheel 그림이었다.
Inner Loop (내 책상에서 빠르게) → Outer Loop (CI 에서 배포 직전 검문) → Production Loop (운영에서 지속 감시) 세 무대가 Golden Dataset (오답 노트)을 매개로 연결되어 있고, 운영에서 발견된 실패가 자동으로 오답 노트에 등록되어 다음 배포의 검문 기준이 된다. 이게 폐쇄 사이클 (Flywheel) 이라
돌리면 돌릴수록 평가 자산이 풍부해진다.
우리는 Outer Loop 까지만 부분 구현됐고 Production Loop 가 아예 없다는 진단.
같은 회귀가 반복되는 이유가 여기 있다. 단 전문 평가자 인력이 우리에게 없으니 개발팀이 직접 골든 셋을 만들면서 시작해야 한다는 현실은 같이 반영해야 한다.
"단 하나의 자연어 요청으로 보안 취약점 6 개가 포함된 코드가 → 자동 수정 → AWS Lambda 배포까지 완료됩니다." — 발표 데모 3
세 가지 라이브 데모가 연달아 이어지는 세션이었는데, 마지막 데모가 충격적이었다. 발표자가 "보안 취약점 6 개가 들어있는 Python 코드를 안전하게 수정하고 배포해줘"라는 한 줄 자연어 요청을 던지자 세 에이전트가 병렬로 분석해서 결과를 합치고, 다른 에이전트가 수정 코드를 작성 하고, 또 다른 에이전트가 배포 승인을 검증 하고, 마지막으로 AWS Lambda 에 배포까지 자동으로 완료됐다.
그리고 "데이터 유출 위험 99% 감소, 수동 리뷰 대비 90% 시간 단축" 같은 ROI 리포트까지 자동 생성한다.
발표자가 정리한 멀티 에이전트가 협업하는 다섯 가지 방식은 이렇다.
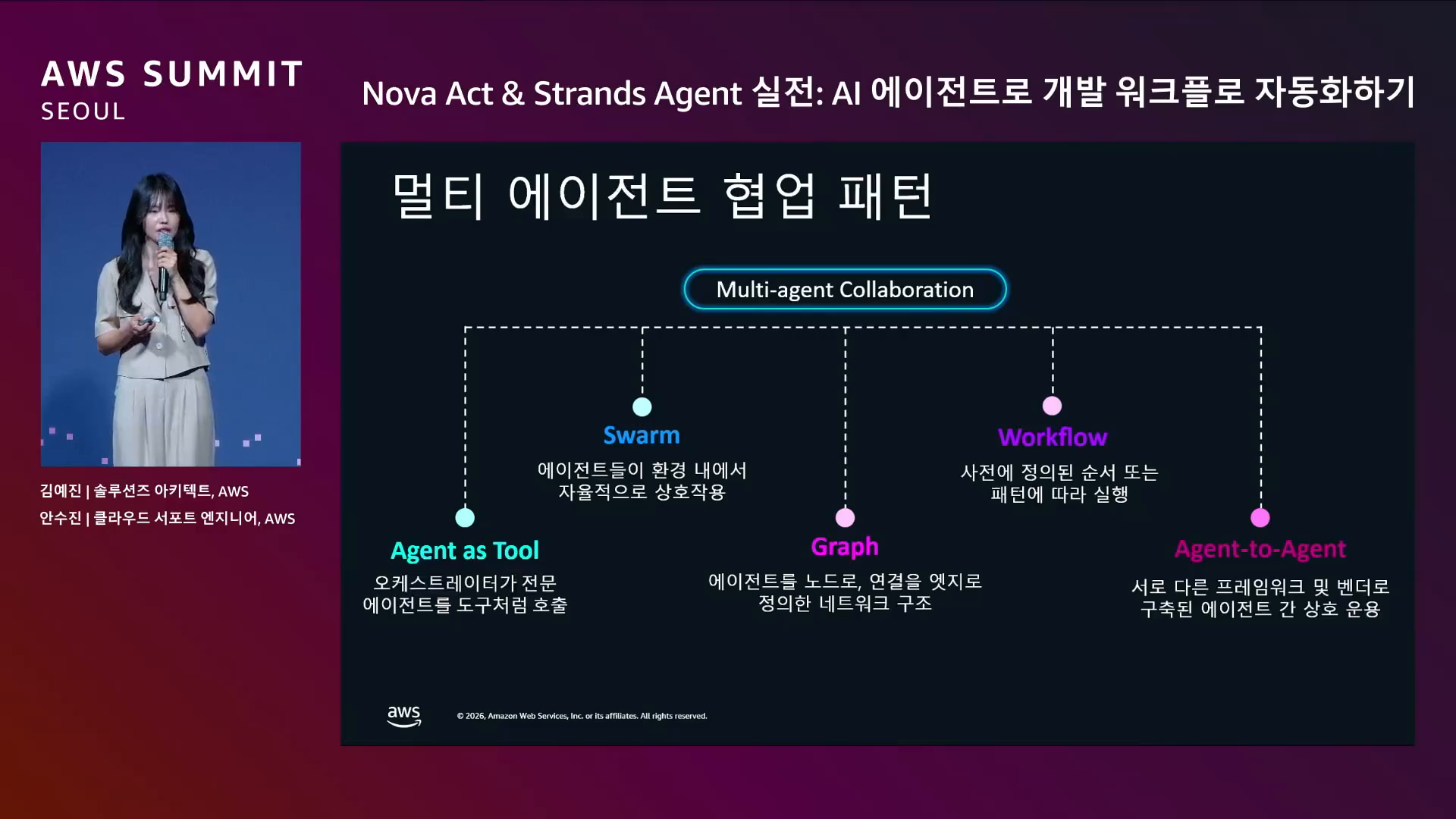



회사 간 협업 같은 탈중앙 상황에 적합하다.
이 다섯 패턴이 한 발표에서 한꺼번에 정리되니, 우리 시스템이 이 중 어디에 위치하는지가 명확해졌다.
우리는 Graph + Routing + 단일 Specialist의 조합 — 즉 명시적 그래프 + 1 종 sub-agent 다.
Swarm도 Hierarchical (Agent as Tool)도 없다.
이게 어떤 한계를 만드는가.
블록 추천 같은 정답이 여럿 가능한 영역 — 시각화 종류, 분석 흐름 같은 — 에서 우리는 LLM 한 번 호출해서 한 개 답을 받는다.
다양성이 부족하다.
그리고 도메인 이해 / 시각화 추천 / EDA / 모델링 / 검증이 모두 단일 Specialist 한 명에게 몰려 있어서, 한 번의 LLM 호출이 다섯 가지 일을 동시에 처리해야 한다.
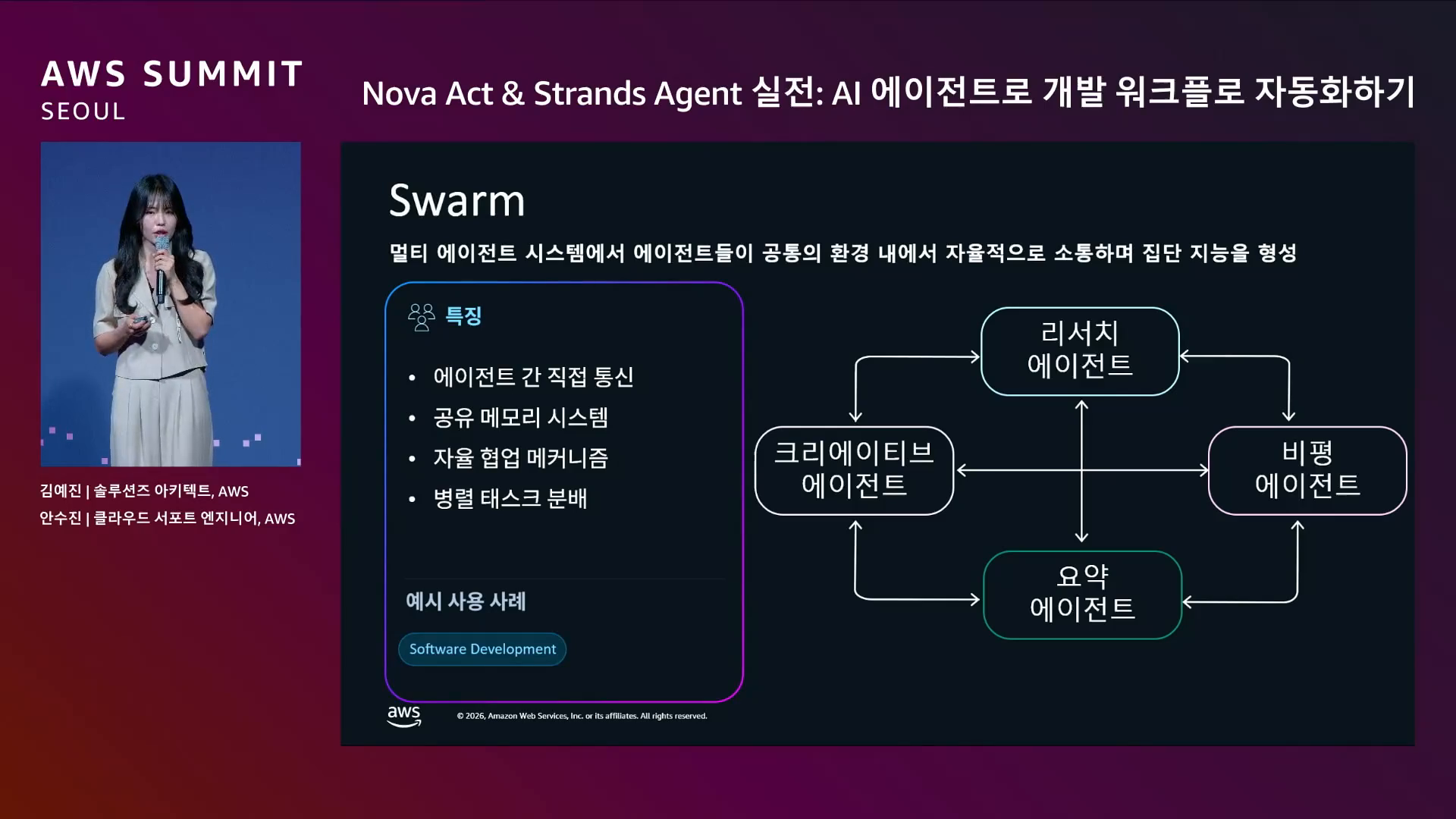
발표가 보여준 정답은 Swarm으로 다관점 추천 + Hierarchical로 영역별 분화.
우리가 가야 할 방향이 여기서 한 번에 잡혔다.
"AI 가 데이터를 이해하려면, 데이터가 AI 를 이해할 수 있도록 준비되어 있어야 합니다." — AWS 강인호 SA
발표 시작 한 줄이 가장 강력했다. MIT 통계까지 끌어와서 — 생성형 AI 프로젝트의 95% 가 파일럿에서 프로덕션으로 못 간다는 사실을 보여주고, 그 95% 의 진짜 원인이 LLM 성능 부족이 아니라 데이터의 준비 상태라는 메시지를 박았다. 책장이 어지러우면 똑똑한 사서도 책을 못 찾는다.
미래에셋 이우람 수석님이 이어받아 ETF·공모펀드·국내채권 PoC 를 풀어줬는데, 운영자의 디테일이 진하게 묻어났다. 발표에서 정리한
핵심 패턴들:
한 번에 만들지 않고 네 단계로 점진적으로. 국제 표준 (FIBO 같은 금융 산업 표준) → 한국 금융 표준 → 사내 용어 매핑 → 현업 전문가 (SME) 가 검증까지.
마지막 SME 검증 단계가 가장 중요하다고 강조 "ETF 가 실적 배당 상품이라는 사실을 SME 가 알고 있어야 검증이 가능합니다".
사람이 빠지면 안 되는 영역이 있다는 점을 명시적으로 인정한다.
"집합투자증권은 예금자보호법에 적용되지 않는다" 같은 문장. 적용되지 않는다라는 부정을 LLM 이 잘못 해석하면 컴플라이언스 사고로 직결된다.
그래서 그래프의 Governed By라는 관계 자체에 "적용 안 됨"을 일급 시민으로 명시한다.
LLM 이 추출하는 게 아니라 처음부터 데이터 모델에 명시되어 있는 형태로.
Intent 분류 (사용자가 뭘 원하는지 분류) 같은 단계는 키워드 매칭 + Semantic Router가 먼저 거른다.
진짜 모호한 케이스만 LLM 에 보낸다. Text-to-SQL 도 마찬가지 LLM 한테 SQL 한 줄을 통째로 짜라고 하면 위험하다.
대신 "어떤 컬럼이 필요한가, 어떤 필터가 필요한가" 같은 핵심 요소만 LLM 에 추출시키고, SQL 문자열은 Python 으로 안전하게 조립한다. LLM 의 비결정성을 받아낼 외부 레이어가 있어야 한다는 사상이다.
비정형 문서 (PDF·약관·계약서) 파싱은 Docling으로 했는데, 그 선택 이유가 인상적이었다.
"빠른 도구는 그림을 너무 많이 잡아서 노이즈가 많고, Docling 은 느리지만 그림을 보수적으로 잡습니다. 정확도가 보장됩니다." 속도가 아니라 정확도 우선, "Garbage In, Garbage Out"인 RAG 파이프라인의 본질에 맞춘 선택이다.,
이 발표가 우리에게 의미하는 바는 단순하다.
우리는 벡터 RAG (ChromaDB) 하나만 쓰고 있는데, 그게 한계라는 사실을 정면으로 깨달은 세션이었다.
미래에셋의 실제 운영 구조는 벡터 + 그래프 + 정형 DB + 문서를 합친 Hybrid Search. 그리고 데이터 모델 자체의 준비 (온톨로지) 가 들어가 있다. 발표 직후 우리도 같은 방향으로 가야겠다는 결정이 잡혔다.
빗썸 발표는 대고객 금융 규제 산업의 AI 도입 보안에 가까웠다. 우리 프로젝트와는 도메인이 다르고 직접 도입할 항목이 적다.
따로 LLM Gateway 거버넌스 / 5 대 보안 기준 / 우리에게 차용할 한 가지를 분리해 두었다.
빗썸은 생성형 AI를 어떻게 안전하게 운영하는가 — Claude Code on Amazon Bedrock
본문에 들고 들어온 한 가지만 짚어둔다
llm_factory 를 단순 dispatch facade에서 거버넌스 레이어 (인증 · 라우팅 · 비용 · 감사 로그) 로 키운다. 02_추가아이디어_참고 가 그 출발점.
도메인은 다 달랐는데 다섯 발표가 결국 같은 다섯 가지 원칙을 반복하고 있었다는 게 컨퍼런스 회고의 핵심이다.
한 줄로 — LLM 은 사람의 자연어를 구조화된 신호로 바꿔주는 통역사 다. 그 다음은 통역된 신호를 안전하게 처리하는 결정적 코드의 영역이다.
다섯 세션이 공통으로 강조한 패턴은 결정적 보장이 필요한 부분에 LLM 을 안 쓰는 것이다.
SQL 유효성 검사, JSON 필드 검증, 의도 분류 같이 명확한 답이 있는 영역에 LLM 을 쓰면 비용도 폭주하고 비결정성도 폭주한다.
미래에셋이 보여준 Text-to-SQL 안전 패턴이 가장 명확한 예시 — LLM 한테 SQL 한 줄을 통째로 짜라고 하지 않고, 어떤 컬럼·어떤 필터가 필요한가 같은 핵심 요소만 LLM 에 추출시키고 SQL 문자열은 Python 으로 안전하게 조립한다.
발표같은 사상이 어떻게 등장했는가미래에셋 GraphRAGText-to-SQL 에서 LLM 은 요소 추출만, SQL 조립은 Python미래에셋 GraphRAGIntent 분류는 키워드 매칭 + Semantic Router 가 먼저, LLM 은 모호한 케이스만AgentCore EvaluationProgrammatic Evaluator — SQL · JSON 검증은 LLM 안 쓰고 Python Lambda 함수에Strands Agents 자율 진화가드레일은 코드 외부에서 정적으로 유지 — 에이전트와 같이 변하지 않는다
보이지 않으면 고칠 수 없다. 에이전트는 스스로 교정하기 때문에 실패가 자동으로 숨겨진다. 그래서 일반 코드보다 훨씬 더 자세한 기록이 필요하다.
AgentCore 발표의 키프레이즈 "에이전트는 소리 없이 실패한다"가 이 원칙의 정수였다.
한 단계에서 잘못 판단해도 다음 단계에서 보정해버리니까 최종 응답은 그럴듯하다.
그래서 응답 한 줄만 보면 안 되고 전체 궤적 (Trajectory) + 모든 도구 호출 + 모든 중간 결과가 기록되어 있어야 한다. 다섯 발표가 각자 자기 방식으로 같은 메시지를 던졌다.
발표어떻게 관측 가능성을 박았나AgentCore EvaluationTrace 기반 평가 — 점수가 3 점이면 왜 3 점인지까지 자동 설명 생성Nova Act + StrandsTrajectory + Action Viewer — 단계마다 스크린샷·사고·좌표·액션까지 S3 에 자동 업로드Strands Agents 자율 진화AgentCore Observability 와 결합해 trace 자동 저장미래에셋 GraphRAG데모 관리자 패널 — Intent / SQL / Graph 검색 / Validation 점수 전 단계 가시화
운영에서 발견된 실패가 자동으로 다음 배포의 회귀 방지 자산이 되어야 한다. 평가는 "끝나고 점수 매기는 활동" 이 아니라 시스템을 진화시키는 입구다.
AgentCore 의 Inner / Outer / Production Loop + Golden Dataset Flywheel 그림이 이 원칙을 한눈에 보여줬다.
Production 에서 실패 발견 → 자동으로 Golden Dataset (오답 노트) 에 등록 → CI/CD 가 다음 배포 직전에 그 노트로 검문 → 통과 못 하면 배포 자체 차단한다.
사이클을 돌릴수록 평가 자산이 풍부해진다. 그래서 Flywheel (관성 바퀴). 다섯 발표가 각자 다른 무게중심으로 같은 사이클을 보여줬다.
발표폐쇄 루프 구현 방식AgentCore EvaluationInner / Outer / Production Loop + Golden Dataset Flywheel — 완전한 사이클AgentCore EvaluationA/B 테스트 (50:50 트래픽) 로 신버전을 안전하게 배포Strands Agents 자율 진화Pattern 3 — Retrieve → Respond → Store. 대화가 쌓일수록 지식 베이스가 풍부미래에셋 GraphRAGValidation 단계 — Weighted Scoring + 안전 Fallback. 점수 낮으면 정해진 대안으로 자동 후퇴
한 줄로 — 한 곳에 고정시키지 마라. 모델은 발전하고, 프레임워크는 진화하고, 데이터 인프라는 바뀐다. 교체 가능성 (replaceability)이 운영 시스템의 필수 조건이다.
빗썸 LLM Gateway 가 이 원칙의 대표 사례다.
모든 LLM 호출이 한 통로를 거치도록 하여, 모델을 교체할 때 코드 여러 곳을 동시에 수정할 필요가 없게 만든다.
Strands가 14 개 모델 프로바이더 자유 전환을 4줄 코드로 시연한 것도 같은 메시지이고, AgentCore 가 "어떤 프레임워크든 / 어떤 모델이든 지원"을 운영 정책으로 명시한 것도 같은 맥락이다.
미래에셋의 Hybrid Search 가 보여준 검색 백엔드도 합성 가능 (벡터 + BM25 + 그래프 + 문서) 한 구조까지 모두 같은 원칙의 다른 표현이다.
발표교체 가능성을 어떻게 구현했나Strands Agents 자율 진화14 개 모델 프로바이더 자유 전환을 4 줄 코드로AgentCore Evaluation어떤 프레임워크든 / 어떤 모델이든 지원하는 추상화빗썸 Claude Code on BedrockLLM Gateway — 모든 LLM 호출이 통과하는 단일 관문미래에셋 GraphRAGHybrid Search — 벡터 / BM25 / 그래프 / 문서 검색 백엔드도 합성 가능
에이전트는 동적으로 진화하지만, 보호막은 정적으로 유지되어야 한다. 같은 코드 안에 함께 있는 가드는 에이전트가 바뀔 때 같이 흔들린다.
세 발표가 같은 사상을 다른 형태로 적용했다.
발표보호막의 위치AgentCore Evaluation3 중 가드레일 — Bedrock Guardrails (입력) + AgentCore Policies (실행) + Agent Evaluations (출력)Strands Agents 자율 진화Anti-Hallucination 프롬프트 — 허용보다 금지를 많게 + 출처 명시 의무미래에셋 GraphRAGGoverned By 관계를 그래프 도메인 모델의 일급 시민으로 (데이터 모델 자체가 막음)
핵심 사상
AI 도구는 진화하지만 보호막은 진화하지 않는다. 사고 시 어디서 뚫렸는지 추적 가능해야 한다.
우리 프로젝트 우선순위는 낮다.
사내 분석 도구라는 도메인 특성상 외부 위협이 작고, 다층 가드레일 명시화보다 Hybrid Search / Topological Faithfulness / 카탈로그 외부화 (MariaDB → MongoDB)가 훨씬 시급하다.
여기까지가 컨퍼런스에서 들은 그대로의 정리였다.
여기서부터는 그 원칙들에 비추어 우리 시스템이 지금 어디에 위치하는가를 객관적으로 진단한다.
진단의 근거는 실제 코드 베이스에서 발췌한 구체 사실들이다.
Mermaid스크롤로 확대 · 드래그로 이동
업계 패턴으로 표현하면 Graph + Routing + Reflection + 1 종 sub-agent. Swarm / Hierarchical 은 없다.
진단의 근거. 본 절의 모든 판단은 ai_agent 코드 베이스에서 직접 발췌한 사실에 근거한다.
column_budget (메타데이터 보호), swap_block 옵션 이식 4 중 게이트, 경량 처리 경로 4 개 (modify_options / fix_link_structure / swap_block / add_block) 가 LLM 우회로 결정적 처리.workflow/respond.py, ~658 줄) 안에 한 덩어리로 섞여 있어 책임 경계가 흐리다.validate 단계를 별도 모듈로 분리. 검증 결과를 프로그래매틱 점수 (숫자) 로 출력하고, 점수 기준 미달 시 자동 fallback. LLM 이 아니라 코드가 결정.trace_id 가 ai_agent → Java EventBus → 프론트 mutation까지 동일하게 묶이지 않는다. 사용자 요청 하나의 흐름을 끝까지 추적하려면 세 군데 로그를 수동으로 맞춰야 한다.trace_id 헤더 통일. 별도로 Trajectory 컬렉션 신설 (MongoDB) 해 호출 → 결과 → 다음 호출의 시퀀스를 자동 적재.tests/golden/ 폴더 신설 + 운영에서 fallback / reject 된 입출력을 자동 적재 → CI 가 매 배포 직전 프로그래매틱 평가. 같은 사고는 두 번 나지 않는다.ai_agent/src/ai_agent/core/llm_factory.py 가 provider 무관 호출 진입점으로 작동. set_provider("ollama") / set_provider("openai") 로 process 단위 admin 전환 가능. ContextVar 기반 async 격리.PythonLlmPurpose = Literal[ "chat", "intent", "plan", "specialist", "reasoning", "error_analysis" ]
llm_factory 위에 Gateway 모듈 신설. 호출자 식별 (어느 모듈이 부른 건지) + purpose 별 라우팅 정책 (Specialist 는 Claude / Intent 는 Haiku 같이) + 비용 / 감사 로그를 MongoDB 한 컬렉션에 적재.data/catalog/block_relations.py 가 카탈로그 단일 출처 에서 자동 build, connection_policy 도메인 분리, column_budget 메타데이터 보호.workflow/data/catalog/ ├── block_data.py ← 블록 메타데이터의 단일 출처 ├── block_relations.py ← 단일 출처에서 자동 build 되는 re-export ├── block_topology.py ├── block_catalog_tdp.py / tsm.py / tvs.py / tdl.py / tdt.py
column_budget / connection_policy / dev_priority_mode 가 각자 다른 위치에 흩어져 전체 보호 그림이 한눈에 안 보이는 상태.ai_agent/src/ai_agent/workflow/demo/modes/datasets/ ├── apartment.py 459 줄 ├── iris.py 415 줄 ├── movies.py 445 줄 ├── steel.py 476 줄 └── titanic.py 428 줄
workflow/data/catalog/ 는 블록 카탈로그. 데이터셋 메타카탈로그 자체가 없다.위 진단의 6 가지 문제 (책임 분리 / trace 단절 / Trajectory 미보유 / 평가 폐쇄 / Gateway 거버넌스 / 데이터셋 메타) 를 한 묶음으로 묶으면 결국 데이터 / 검색 / 저장 레이어가 전부 다 바뀌어야 한다.
Mermaid스크롤로 확대 · 드래그로 이동
Mermaid스크롤로 확대 · 드래그로 이동
1. ChromaDB → Qdrant (Vector DB 교체). ChromaDB 는 임베딩 캐시 한 채널까지만.
Qdrant 는 sparse + dense hybrid를 1 급으로 지원하고 payload filter (구조화 필터)가 있어, 한 DB 안에서 벡터 + 키워드 + 메타 필터를 동시에 굴릴 수 있다.
Rust 기반이라 속도도 압도적이다.
2. Graph DB 신규 도입 (Neo4j Community). Block ↔︎ Column ↔︎ DomainTerm 관계가 현재 Python 함수에 내장되어 있어 질의가 불가능하다.
그래프 DB로 옮기면 "보험금 → ClaimAmount 컬럼 → 숫자형 컬럼 → 이 컬럼에 쓸 수 있는 블록" 같은 다단계 관계 추적이 한 쿼리로 가능. 종합정리 2-11. Hybrid Search의 그래프 채널이 작동하려면 필수적이다.
3. MariaDB → MongoDB Community (분석 DB 전환). MariaDB 는 분석 결과의 행 단위 저장에는 충분했지만, 카탈로그 / 컨트랙트 / Trajectory / 데이터셋 메타처럼 스키마가 자주 진화하는 데이터에는 확장 제약이 있다.
MongoDB Community로 묶으면 카탈로그 + 메타 + 분석 + Trajectory 가 한 저장소 안에 깔리고, 컬렉션별 스키마 진화가 자유롭다. 단일 컬렉션 단위 백업·인덱싱·복제가 운영 부담을 줄인다.
영역선택라이센스책임Agent FrameworkLangGraphMITPlan / Validate / Respond / Reflect + Hierarchical TeamsVector DBQdrantApache 2.0의미 인덱스 (임베딩 검색) — ChromaDB 에서 전환Graph DBNeo4j CommunityGPLv3 (서버)관계 인덱스 (Cypher traversal) — 신규 도입Document DBMongoDB CommunitySSPL원본 단일 출처 (카탈로그 / 컨트랙트 / 사용 통계 / 데이터셋 메타)Hybrid SearchLangChain EnsembleRetriever + 직접 RRFMIT4 채널 합의 (vector + BM25 + graph + structured)Embeddingbge-m3MIT텍스트 → 벡터 변환Keyword Searchrank-bm25Apache 2.0정확 키워드 매칭LLMOpenAI GPT-4o-mini (기본) + Bedrock Claude (선택)API추론 / 응답 생성프로젝트 분석 DBMongoDB CommunitySSPL분석 결과 / 사용자 / 세션 lineage / Trajectory 기록 — MariaDB 에서 전환
변경 한눈에.
종류항목이유신규 도입Neo4j Community그래프 채널 부재 → 다단계 관계 추적 불가신규 도입rank-bm25 / bge-m3 / LangChain EnsembleRetrieverHybrid Search 4 채널 + RRF 합산교체ChromaDB → Qdrant단일 채널 → sparse+dense hybrid + payload filter유지MariaDB / MongoDB Community스키마 진화 자유 + 카탈로그·메타·Trajectory 통합 저장
이 변경은 한 번에 가지 않는다. 동작이 깨지지 않도록 읽기 전용 추가 → 읽기 라우팅 전환 → 쓰기·결정 경로 전환의 3 단계로 진행한다.
컨퍼런스 다섯 세션을 보고 돌아와 우리 시스템의 다음 단계를 어디로 잡을지 정리한 결과, 가장 핵심이 되는 두 갈래로 우선순위를 좁혔다. 본 장에서는 그 두 갈래만 다룬다.
검색·저장소 아키텍처와 에이전트 패턴 진화.
각 갈래는 지금은 어떤 한계가 있고 → 어디로 가야 하며 → 어떤 발표에서 영감을 받았는가 순서로 풀어둔다.
Mermaid스크롤로 확대 · 드래그로 이동
Mermaid스크롤로 확대 · 드래그로 이동
DB책임우리 프로젝트 컬렉션MongoDB (Document)카탈로그 / 컨트랙트 / 인스턴스 / 사용자 커스터마이즈block_catalog, block_contracts, block_manifests, intent_exemplars, usage_statsGraph DB (Neo4j 또는 KuzuDB)관계 traversal — requires_before / often_paired / 도메인 어휘 매핑Block-REQUIRES_BEFORE-Block, DomainTerm-MAPS_TO_COLUMN-ColumnVector (Qdrant 또는 Chroma 유지)의미 검색block_catalog_vec, domain_term_vec, intent_exemplar_vecBM25 (rank-bm25)키워드 정확 매칭inline (별도 DB 없이)
영감 받은 세션 — 미래에셋 GraphRAG (벡터 + 그래프 + 정형 RDS) 가 정확히 같은 구조로 운영 중이라는 사례. insurance-ontology-kor 오픈소스가 Bedrock + Neptune + OpenSearch의 동일 패턴을 코드로 공개하고 있음.
컨퍼런스 후 정리한 비교표:
제품라이센스강점Hybrid우리 프로젝트 적합도ChromaDB (현재)Apache 2.0학습 곡선 0, embed 가능, LangChain 통합 1급약함★★★ (PoC)QdrantApache 2.0압도적 속도, payload filter 1급, sparse+dense hybrid1급★★★★★WeaviateBSD-3hybrid 1급, GraphQL, 모듈 시스템1급★★★★MilvusApache 2.0분산, billion-scale부분★★ (운영 무거움)pgvectorPG Lic.SQL 통합, ACID부분★★ (별도 Postgres 필요)OpenSearchApache 2.0search engine + vector + BM251급★★★ (JVM 무거움)
→ Qdrant 선택 근거 — Rust 기반 압도적 속도, sparse+dense hybrid 1 급 지원, payload filter (structured filter) 1 급, on-prem 운영 부담 적음.
측면현재 (vector only)Hybrid (4 채널 + RRF)근거검색 정확도단일 신호 의존다채널 합의Microsoft GraphRAG 논문이 보고하는 정확도 상승 패턴재현율의미 유사도만 포착관계까지 포착graph traversal 로 vector 가 놓친 관계 발견조기 리턴 정확도위험 (단일 신호)신호 합의 후 결정한 채널 오류가 결정 못 함카탈로그 변경 반영재시작 필요핫리로드 (DB 단위 갱신)인프라 분리의 부산물
recommend_block_options) 에 몰림.Mermaid스크롤로 확대 · 드래그로 이동
각 sub-agent 는 명확한 input / output 계약으로 메인 그래프와 분리. 메인은 LangGraph 정확도 가드 유지.
영감 받은 발표 — Nova Act + Strands Agent 실전의 Hierarchical / Agent as Tool 패턴. 단일 슈퍼 에이전트에 모든 책임 몰지 않고 sub-team 분화하는 사상.
블록 추천 같은 ill-defined 생성 문제 — 정답이 여럿 가능한 영역 — 에서:
영감 받은 발표 — Strands Swarm 패턴. 다관점 분석·교차 검증.
위 두 갈래 외에 업스테이지 sLLM 분업 · LLM Gateway 거버넌스 같은 추후 검토용 발상은 참고 노트 02_추가아이디어_참고 에 분리해 두었다.
다섯 세션 + 부스 + 후속 오픈소스 조사에서 우리 시스템에 도입하기로 잡은 기술·아이디어 항목만 한자리에 모았다. 일정·수치 목표는 본 문서에서 다루지 않는다 — 무엇을 어디에 도입할 것인가까지가 본 문서의 범위.
영역기술·도구한 줄 의의Vector DBQdrant (ChromaDB 대체)운영급 인덱스 분할·필터링·HNSW 튜닝 지원Graph DBKuzuDB / Neo4j카탈로그 관계 (requires_before 등) 를 그래프 질의로 추론Document StoreMongoDB카탈로그·컨트랙트 핫리로드 (서버 재시작 → 컬렉션 단위 갱신)BM25 인덱스OpenSearch 또는 Elasticsearch키워드·약어·코드 시그니처 보존Rank FusionRRF (Reciprocal Rank Fusion)4 채널 결과를 결정론적으로 합산LLM Facadellm_factory.py 확장 (Phase A~E)인증·라우팅·비용·감사 흡수, 호출자 무관ObservabilityOpenTelemetrygRPC → Java EventBus → 프론트 trace_id 일관 부착Agent FrameworkLangGraph (현재) + Strands 검토모델 드리븐 vs 그래프 드리븐 양쪽 가능성 유지Multi-agent 패턴Hierarchical + SwarmSpecialist 1 종 → 5 종 분화 / alternatives 다관점 합의Document ParserDocling + DocumentFigureClassifier + TableFormer파싱 품질이 RAG 상한선 결정MCPFastMCPClaude Desktop / Cursor 에서 우리 프로젝트 직접 호출 (장기)
아이디어출처우리 프로젝트 반영 지점Hybrid Search 4 채널 (Vector + BM25 + Graph + Document)미래에셋 GraphRAG검색·저장소 아키텍처 전면 재구성카탈로그·컨트랙트 MongoDB 화미래에셋 GraphRAG (운영 분리 사상)block_catalog_* / block_relations 운영 분리Hierarchical Sub-agents (Domain · 시각화 · EDA · 검증)Nova Act + Strands 실전 (Agent as Tool)Specialist 단일 → 5 종 분화Swarm 패턴 — 다관점 합의Nova Act + Strands 실전alternatives (정답 다수 가능 영역) 다관점 검증Inner / Outer / Production LoopAgentCore Evaluation운영 실패 → 회귀 자산 자동 변환Golden Dataset Flywheel (개발팀 자력 운영)AgentCore Evaluation + 현실 (전문 분석가 부재)시연 회귀 케이스 누적Ground Truth 3 형태 (Assertion / Expected Response / Expected Trajectory)AgentCore Evaluation평가 케이스 분류 표준화다층 가드레일 (Bedrock Guardrails + AgentCore Policies + Agent Evaluations)Strands Agents 자율 진화응답 함수 책임 분리 (5 모듈)AI-Ready Data + 온톨로지 4 단계 (EAS → EAS-S → ER → ER-S)미래에셋 GraphRAG데이터셋 메타카탈로그 + 의미 분류기계층적 요약 (페이지 → 이미지·테이블 단위)doc-parser 오픈소스 (부록 C)블록 → 단계 → 워크플로 3 계층 요약다차원 평가 (Intent / Vector / Template / Subgraph + LLM-as-Judge)insurance-ontology-kor 오픈소스 (부록 C)Specialist 평가 확장LLM Gateway 4 역할 (API 호환 / 인증 / 라우팅 / 비용)빗썸 Claude Code on Bedrockllm_factory 확장 청사진sLLM/LLM 분업 발상업스테이지 부스 (부록 B)참고만 — 모델 크기를 역할로 나눈다는 일반 패턴
AWS Summit Seoul 2026 의 AI Agent 세션 다섯 개는 금융 / 보안 / 개발자 도구 / 일반 에이전트 / 평가 인프라로 도메인이 모두 달랐는데도 — 같은 다섯 가지 원칙으로 수렴했다.
서두에 적었듯 — 이번 컨퍼런스의 가장 큰 수확은 두 가지였다.
첫째 — 우리가 가던 방향이 옳았다는 검증. 코엑스 시연까지 구축한 벡터 RAG / 단일 Specialist / LangGraph 그래프 드리븐 / 카탈로그 7-tier 등록 — 다섯 사례 모두 비슷한 골격 위에 있었다. 도메인은 달랐어도 결정론 우선 / 그래프 기반 추론 / Specialist 분화의 시작점 / 카탈로그 단일 출처 7-tier 등록이라는 뼈대는 같았다.
둘째 — 멈춰있던 다음 단계의 발견. 우리가 다음 발걸음을 못 떼던 자리를 다섯 발표가 정확히 짚어줬다. 컨퍼런스 직후 정리한 다음 단계 일곱 갈래는 다음과 같다.
추후 검토용 발상 두 가지 (업스테이지 sLLM 분업 / LLM Gateway 거버넌스) 는 별도 참고 노트 02_추가아이디어_참고 에 정리해 두었다.
이 다음 단계들이 이미 하던 좋은 것 위에 새 레이어로 얹힌다. 기존 시스템을 부수지 않는다. 읽기 전용 추가 → 읽기 라우팅 전환 → 쓰기·결정 경로 전환의 3 단계로 진행한다. 시연이 깨지지 않으면서 다음 단계로 간다.
다섯 사례가 같은 그림을 그리고 있다는 사실 자체가 우리에게 가장 큰 자신감을 준다. 우리만 헤매고 있던 게 아니라, 같은 답을 모두가 같은 시점에 발견하고 있었다. 그리고 우리가 가던 방향이 그 답의 일부였음이 확인됐다.
본 문서의 범위는 기술·아이디어 식별까지. 일정·수치 목표는 별도 작업 노트에서 다룬다.
본 문서는 컨퍼런스 다섯 세션의 핵심 원칙 + 우리 프로젝트 고도화 방향으로 본문을 한정했다.
부스 인사이트는 본문에서 빼고 별도 노트로 분리했으니, 필요한 항목만 따로 열어 보면 된다.
github.com/Gyuho-Song/insurance-ontology-kor)github.com/Gyuho-Song/doc-parser)summitseoul.awslivestream.comstrandsagents.comaws.amazon.com/bedrock/agentcoreqdrant.tech · Weaviate — weaviate.io · Neo4j — neo4j.com · KuzuDB — kuzudb.comgithub.com/DS4SD/docling · FastMCP — gofastmcp.com